产品动态
开源大数据平台E-MapReduce全新能力升级,新用户免费体验
产品简介
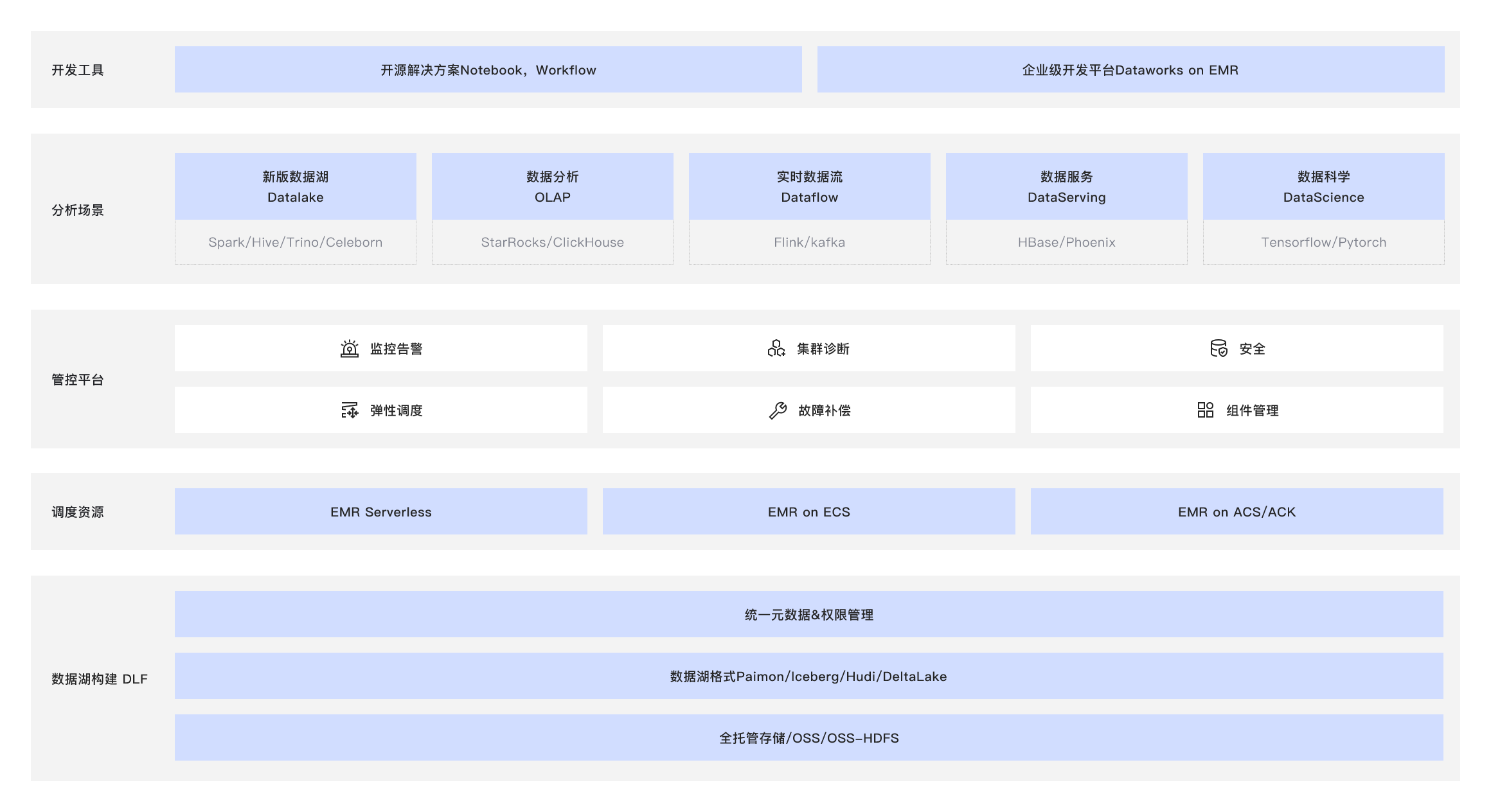
产品优势
开源大数据平台 E-MapReduce(简称“EMR”)为客户提供简单易集成的Hadoop、Hive、Spark、StarRocks、Flink、Presto等开源大数据计算和存储引擎,支持on ECS、on ACK以及Serverless多种部署形态,选择EMR,您可以轻松构建具备以下优势的云上服务。

100%兼容开源社区组件,性能较开源版本提升3-5倍
100%采用社区开源组件,随开源版本升级迭代。适配开源组件,避免开源组件之间的版本兼容性问题。基于开源组件优化和增强阿里云部署环境,性能远高于开源版本。

分钟级搭建大数据计算环境,支持智能诊断分析
分钟级搭建大数据计算环境,支持一键调整计算资源规模,无需人工部署和启动服务。完善的监控和告警体系,支持智能诊断分析,大幅缩减排障路径,提升运维效率。

计算资源按需使用,自动数据冷热分层存储,支持抢占式实例等多种优化手段
计算资源按需使用,降低闲置算力成本;自动数据冷热分层存储,降低单位存储成本。丰富的运维辅助工具,智能诊断分析,便捷管理大数据平台,降低运维成本;支持阿里云抢占式实例、预留实例券(RI)、混合计费等多种成本优化手段,进一步压缩成本支出。
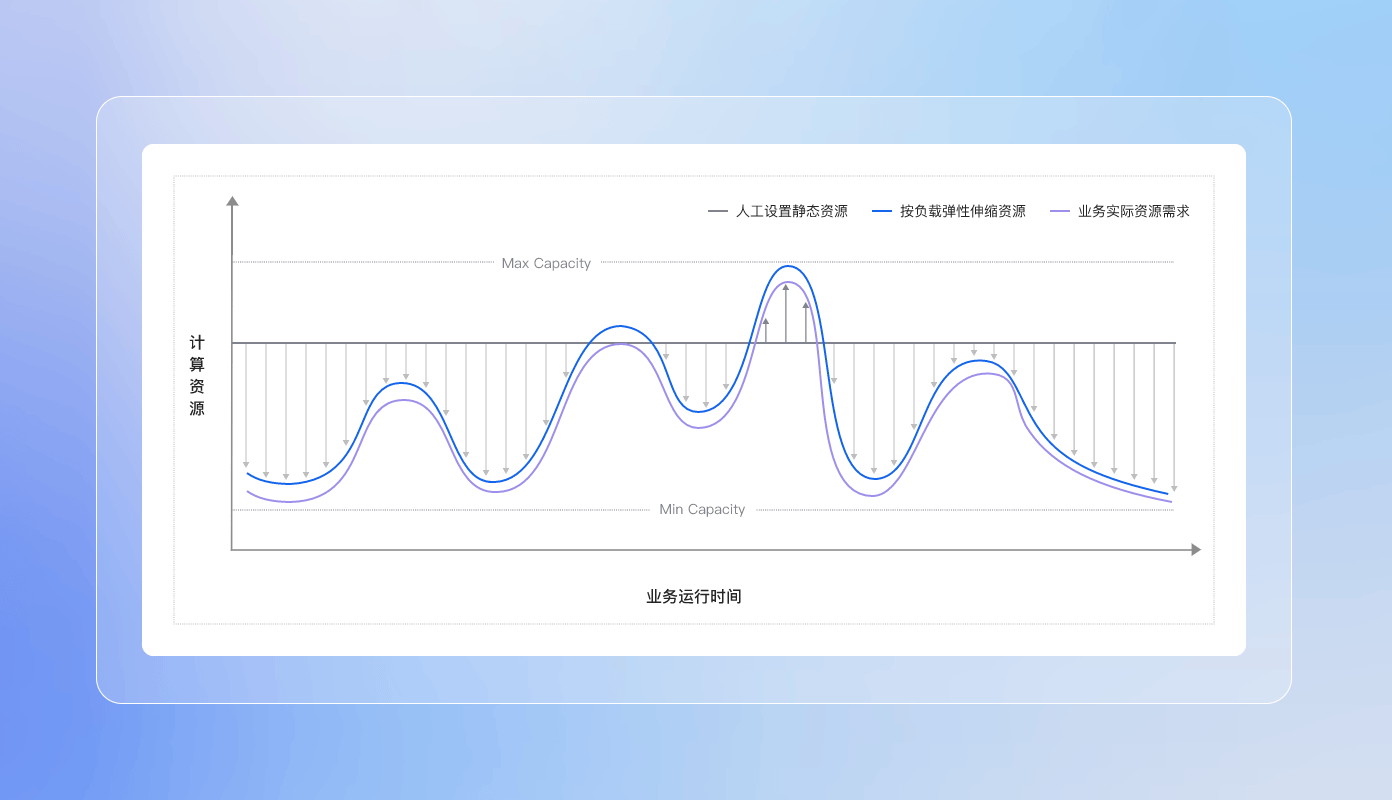
支持按负载/时间,灵活配置规则;分钟级弹性伸缩,支持多种弹性资源类型
支持按负载/时间,可灵活的根据业务场景配置规则。分钟级弹性伸缩,极高效率,响应快速变化的业务诉求。支持多种弹性资源类型。

安全合规
阿里云EMR是一种托管的开源大数据处理服务,支持弹性扩展,处理PB级海量数据,并提供ACL、加密、Kerberos等安全机制,让用户无需搭建和管理复杂的大数据环境,通过简单配置就可启动使用,与其他大数据产品深度集成,可一站式处理和分析数据。

网络和基础设施安全
访问隔离:通过安全组管理,对集群内的ECS实例进行出方向和入方向的网络控制,满足业务网络保护要求。
存储传输加密:通过数据盘加密,对动态数据传输及静态数据加密,保护数据的隐私性和自主性,为业务数据提供安全边界。

系统安全
权限管控:通过阿里云通用RAM访问控制鉴权,控制对EMR集群资源的操作权限。
操作审计:通过阿里云Action Trail操作审计查询用户操作EMR产生的管控事件,满足业务实时审计、问题回溯分析需求。

容灾安全
数据容灾:数据支持多副本存储,任一数据出现问题时,副本数据自动切换恢复,保证数据的可靠性。
服务容灾:通过核心组件高可用部署,保障任一服务节点故障时,能够自动切换,保证服务不受影响。
客户案例
开源大数据平台EMR为您提供安全可靠、弹性伸缩的云原生大数据平台,在不同行业内都沉淀了不少客户案例,为广大客户解决了诸多业务挑战。