大模型
产品
解决方案
文档与社区
权益中心
定价
云市场
合作伙伴
支持与服务
了解阿里云
AI 助理
备案
控制台
< 查看全部产品
云消息队列 Kafka 版
播放视频
云消息队列 Kafka 版是阿里云基于 Apache Kafka 构建的高吞吐量、高可扩展性的分布式消息队列服务,广泛用于日志收集、监控数据聚合、流式数据处理、在线和离线分析等场景,是大数据生态中不可或缺的产品之一,阿里云提供全托管服务,用户无需部署运维,更专业、更可靠、更安全。
【预约直播】3月27日 ApsaraMQ x Confluent|云原生 Kafka 线上沙龙
立即购买
产品控制台
产品文档
产品定价
价格计算器
购买云消息队列 Confluent 版
产品规格
产品优势
产品功能
应用场景
客户案例
更多产品与服务
文档与工具
最新活动
限时有奖
截至4月10日,参与云原生 Kafka 问卷调研,领取精美定制周边礼品!
组合优惠
Flink + Kafka 组合购套餐优惠,轻松实现云上实时流处理和分析
新客专享
云消息队列 Kafka 版全规格 1 个月订单,新用户首月 5 折!
新客专享
云消息队列 Confluent 版全规格 1 个月订单,新用户首月 1 折!
重要内容
重磅发布
云消息队列 Kafka 版 Serverless 实例发布!
最佳实践
从开源 Kafka 迁移到云消息队列 Kafka
最佳实践
Kafka 性能压测快速方案
最佳实践
基于 FC 实现阿里云 Kafka 消息内容控制 MongoDB DML 操作
产品规格
云消息队列 Kafka 版(包年包月)
Kafka 支持 0.10.x ~ 2.x 版本,默认部署的 0.10.x 版本
询价中
云消息队列 Kafka 版(包年包月)
专业版独享集群默认部署的 0.10.x 版本,支持无缝升级。
询价中
云消息队列 Kafka 版 Serverless 系列
2倍流量弹性,无限存储,节省费用30%
询价中
产品优势
高弹性超大规格支持
深度优化内核,解决开源版本千级分区性能瓶颈,支持万级分区性能不受损;支持秒级扩容;支持最高 50 GB/s 流量写入
免运维、易观测
全托管开箱即用,兼容主流开源版本和多语言客户端,支持一键升降配、订阅关系可视化、消息查询回溯、数据大盘和监控告警
领先的高 SLA 保障
支持灰度升级、升级/拖冷数据等极端场景写优化保障;全自动巡检运维体系保障,服务可用性达 99.95%,数据可靠性达 99.999999%
支持丰富的数据生态
提供全托管、免运维 Connector,支持连接海量云产品以及自建大数据生态产品,轻松实现数据集成和计算
产品功能
丰富的实例类型
针对不同业务规模以及不同读写流量比例场景提供场景匹配的实例规格
标准版高写实例
适用业务规模较小、成本敏感的轻量应用场景,实现低成本轻松上云
专业版高写实例
适用大规模数据写入场景,提供高达 50 GB/s 高水位数据写入,性能更强劲
专业版高读实例
适用写少读多的大规模数据分发场景,提供高达3GB/s的数据读取带宽
全托管免运维服务
云消息队列 Kafka 版丰富的运维经验,面向用户提供体系化的管理配套,轻松排查和解决问题
HouseKeeping(健康巡检组件)
跨可用区、多副本数据冗余,数据可靠性 99.999999%,服务可用性 99.95%
业务监控与告警
在海量消息堆积的情况下,始终保持 Kafka 集群的消息收、发的高吞吐能力
Open API(RESTful)
完善的管控类 Open API 帮助用户实现自助资源管理和运维,采用 RESTful 标准,灵活便捷
数据回溯
支持对已消费过的消息进行重新回放或清除堆积的消息,是帮助用户故障恢复的利器
全托管、免运维 Connector 支持
一键配置即可连接海量云产品以及自建大数据生态产品,轻松实现数据集成和计算
FC Connector
通过配置即可实现 Kafka 数据触发 FC 函数运行
MaxCompute Connector
支持海量数据从 Kafka 直接导入 MaxCompute 数据表,方便后续离线计算处理
OSS Connector
支持 Kafka 数据直接写 OSS 存储,实现数据长期低成本存储
Mysql Connector
通过配置实现 Mysql 数据表变同步到 Kafka Topic,实现数据库增量变更同步等场景
海量数据生态对接
云消息队列 Kafka 版兼容标准规范,支持海量开源组件或者云产品连接
Logstash 数据收集
云消息队列 Kafka 版支持连接自建 Logstash服务,实现丰富的数据源导入和导出
Filebeat 日志收集
云消息队列 Kafka 版支持连接自建 Filebeat 日志采集,经由 Kafka 流转到后方 ES 服务
Hbase、Spark 数据处理
云消息队列 Kafka 版数据导入 Hbase 等存储,实现低成本存储和计算分析
Flink 实时数仓
云消息队列 Kafka 版支持数据流转到 Flink,实现ETL处理、实时数据分析等业务
数据安全
支持阿里云主子账号、鉴权与授权机制,提供企业级的安全防护
访问控制
VPC 网络隔离,对每次消息收、发请求进行安全访问控制,确保消息的安全性
主子账号
全面支持 RAM 主子账号、黑白名单、STS 等功能,提供授权能力
数据安全
SASL 用户身份认证与 SSL 加密传输,确保数据传输过程中不被窃取或篡改,保证客户数据的安全
应用场景
构建日志分析平台
网站活动跟踪
流计算处理
数据中转枢纽
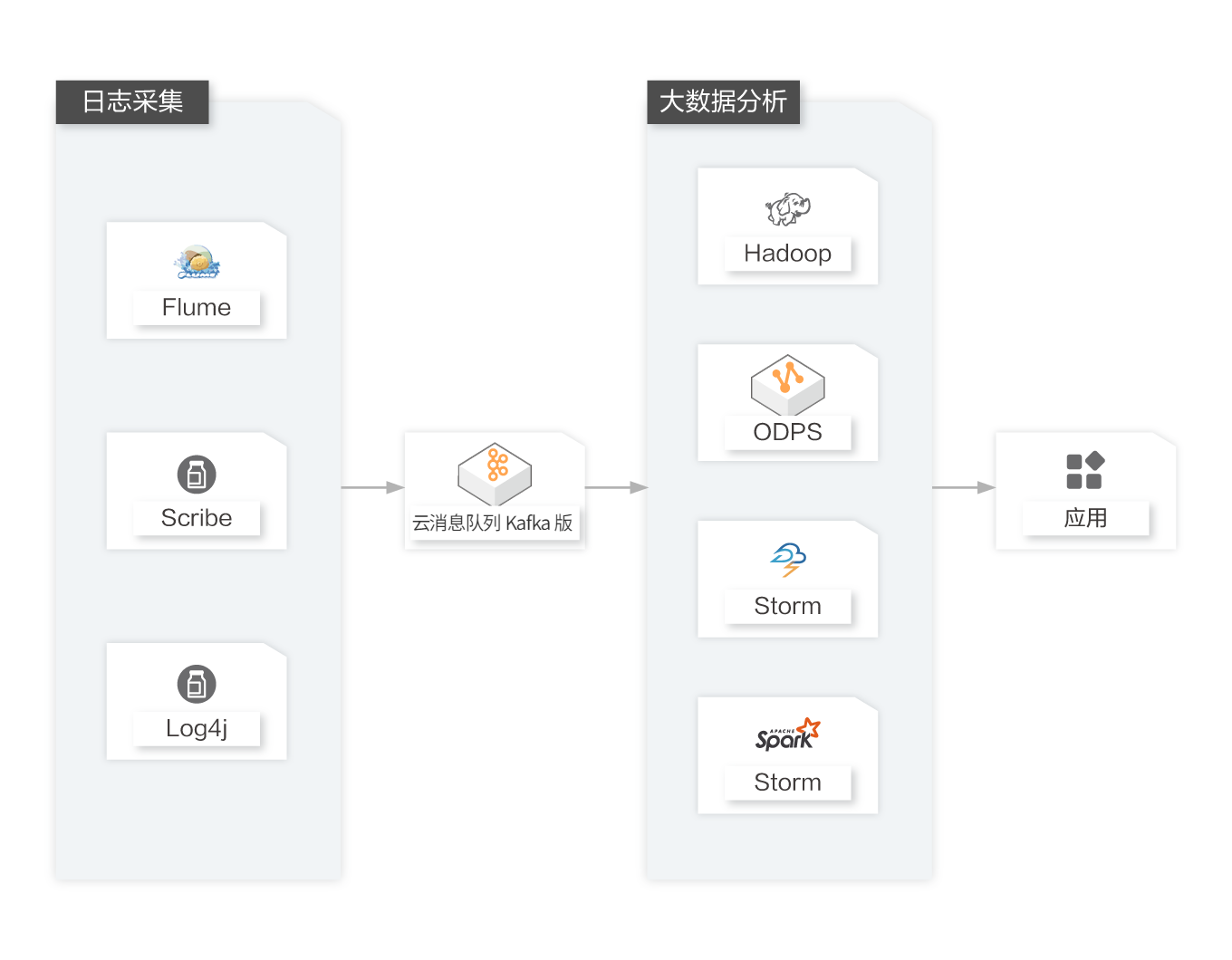
构建日志分析平台
淘宝、天猫平台等公司每天都会产生大量的日志。Kafka 性能高效,采集日志时业务无感知以及Hadoop/ODPS 等离线仓库存储和 Storm/Spark 等实时在线分析对接的特性决定它非常适合作为"日志收集中心"。
能够解决
应用与分析解耦
构建应用系统和分析系统的桥梁,并将它们之间的关联解耦;
在线/离线分析系统
支持实时在线分析系统和类似于Hadoop之类的离线分析系统;
推荐搭配使用
云消息队列 MQ
应用实时监控服务 ARMS
Elasticsearch
网站活动跟踪
通过云消息队列 Kafka 版可以实时收集网站活动数据(包括用户浏览页面、搜索及其他行为等)。发布-订阅的模式可以根据不同的业务数据类型,将消息发布到不同的 Topic;还可通过订阅消息的实时投递,将消息流用于实时监控与业务分析或加载到 Hadoop、ODPS 等离线数据仓库系统进行离线处理。
能够解决
高吞吐
网站所有用户产生的行为信息极为庞大,需要非常高的吞吐量来支持;
大数据分析
可对接 Storm/Spark 实时流计算引擎,亦可对接 Hadoop/ODPS 等离线数据仓库系统;
推荐搭配使用
云服务器 ECS
负载均衡 SLB
实时计算 Flink 版
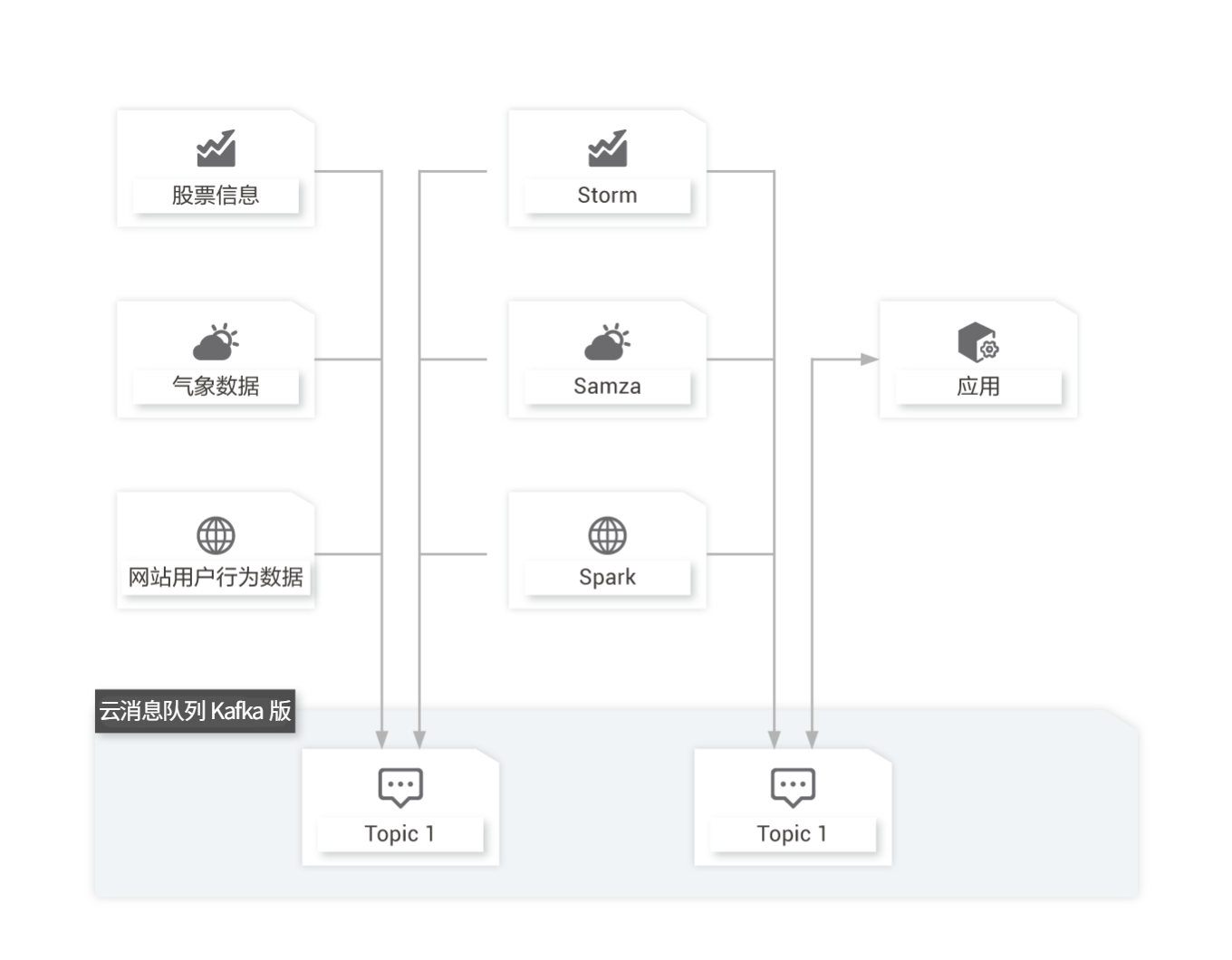
流计算处理
股市走向分析、气象数据测控、网站用户行为分析等领域,由于数据产生快、实时性强、数据量大,所以很难统一采集并入库存储后再做处理,这便导致传统的数据处理架构不能满足需求。而云消息队列 Kafka 版以及 Storm/Samza/Spark 等流计算引擎的出现,可以根据业务需求对数据进行计算分析,最终把结果保存或者分发给需要的组件。
能够解决
高可扩展性
由于数据产生非常快且数据量大,需要非常高的可扩展性;
流计算引擎
可对接开源 Storm/Samza/Spark 以及 EMR、Blink、StreamCompute 等阿里云产品;
推荐搭配使用
实时计算 Flink 版
云消息队列 MQ
应用实时监控服务 ARMS
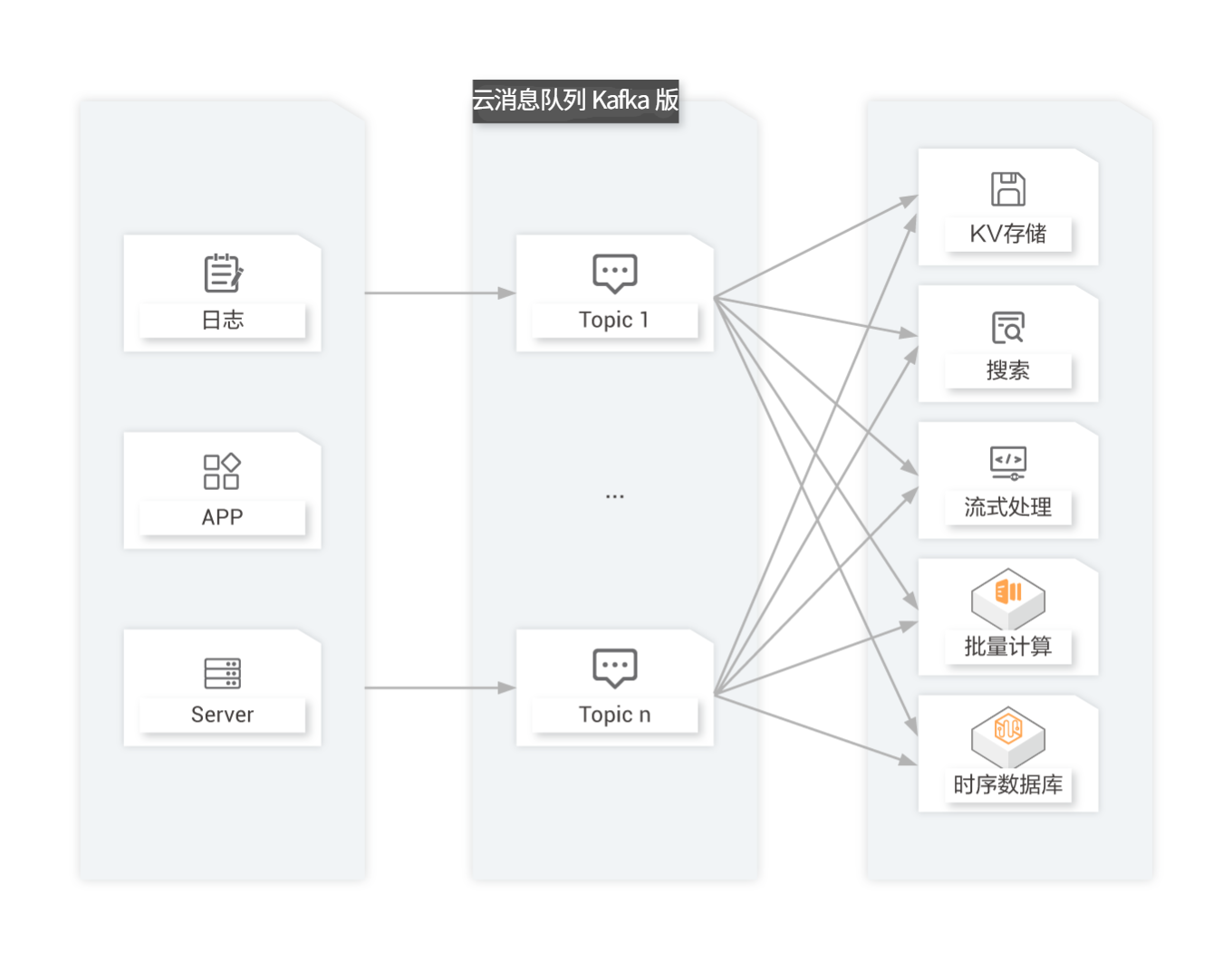
数据中转枢纽
近年来KV存储(HBase)、搜索(ElasticSearch)、流式处理(Storm/Spark Streaming/Samza)、时序数据库(OpenTSDB)等专用系统应运而生,产生了同一份数据集需要被注入到多个专用系统内的需求。利用云消息队列 Kafka 版作为数据中转枢纽,同份数据可以被导入到不同专用系统中。
能够解决
一对多消费模型
发布/订阅模型,支持同份数据集能同时被消费多次;
同时支持实时和批处理
本地数据持久以及PageCache,在无性能损耗的情况下能同时传送消息到实时和批处理消费者;
推荐搭配使用
MaxCompute
云消息队列 MQ
Elasticsearch
客户案例
曹操出行
云消息队列 Kafka 版 Serverless 系列凭借其秒级弹性扩展和按需付费的优势助力曹操出行实现灵活扩缩容,保证服务的敏捷性和稳定性,并节省超过 20% 的成本。
查看详情
道旅科技
云消息队列 Kafka 版作为道旅科技的核心技术支撑,为其提供了坚实的业务保障,助力道旅科技在业务效率和成本优化上持续取得突破,更高效地处理大规模数据流,从而推动旅游行业的创新与发展。
查看详情
大搜车
大搜车已经搭建起比较完整的汽车产业互联网协同生态。随着业务的快速发展,大搜车遇到了消息量大幅增加、异地消息同步等一系列的问题,需要更稳定可靠的商业版 Kafka 产品,减少运维工作量,利用云消息队列 Kafka 版对接大数据生态,即开即用,快速扩容,可靠性更高。
查看详情
小麦助教
开源自建 Kafka 运维投入大,在大规模场景下稳定性无法保障,开源 bug 没有解决,同时 SLA 无法保障。而云消息队列 Kafka 对产品内核进行全方位优化,解决开源产品长期以来的痛点,免运维、低成本、更稳定、大数据领域优选数据通道。
查看详情
骑士卡
使用云消息队列 Kafka 版,无论在生产环境还是本地开发测试环境,都可以直接使用云产品,减少通用产品依赖,让团队专注于业务的开拓实现,极大的提升了团队工作效率。
查看详情
更多产品与服务
云消息队列 RocketMQ 版
基于 Apache RocketMQ 构建的低延迟、高并发、高可用、高可靠、高弹性的分布式“消息、事件、流”统一处理平台
查看详情
轻量消息队列(原 MNS)
易集成、可扩展的轻量消息队列,简单队列模型、Serverless 弹性高并发,低成本快速构建分布式松耦合系统,高效传递数据和通知消息
查看详情
云消息队列 MQTT 版
提供移动互联网、物联网、互动直播等场景的原生支持,万物互联,端与云双向通信,支撑千万级设备同时在线
查看详情
云消息队列 RabbitMQ 版
兼容 AMQP 0-9-1 协议,解决了开源的稳定性痛点,同时提供按量付费的售卖模式,具备开箱即用、无需评估容量等优势
查看详情
文档与工具
快速入门
如何快速使用云消息队列 Kafka 版
产品文档
云消息队列 Kafka 版所有文档
API & SDK
云消息队列 Kafka 版开发者指南
最佳实践
云消息队列 Kafka 版发布者与订阅者的最佳实践