
「Python」爬虫-1.入门知识简介
持续创作,加速成长!这是我参与「掘金日新计划 · 10 月更文挑战」的第13天, 点击查看活动详情本文主要介绍了爬虫相关的入门知识。本文目录爬取小猫的图片写入文件相关正则表达式简介bs4解析前言关于爬虫的书籍:Python爬虫书籍--崔庆才著(第一版)阿里云盘获取,2025年失效这本书已经...

10个经典Python爬虫入门实例!你还不知道吗
伙伴们学习python爬虫,准备了几个简单的入门实例,分享给大家。代码中给出了注释,并且可以直接运行哦如何安装requests库(安装好python的朋友可以直接参考,没有的,建议先装一哈python环境)windows用户,Linux用户几乎一样:打开cmd输入以下命令即可,如果python的环境...


python编程-20:网络爬虫requests库入门
python编程-20:网络爬虫requests库入门
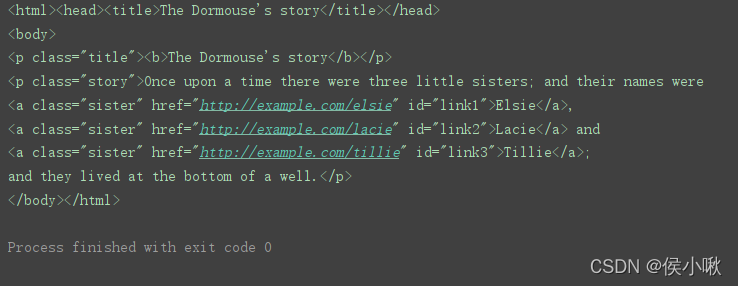
python爬虫BeautifulSoup模块解析数据入门
python爬虫使用BeautifulSoup模块解析数据入门 1.准备 首先进行模块安装: pip install BeautifulSoup4 因为BeautifulSoup4依赖于lxml库,所以也要安装lxml库才能正常使用。 代码示例 from bs4 import BeautifulSo...

python编程-20:网络爬虫requests库入门
python编程-20:网络爬虫requests库入门
带你读《Python网络爬虫从入门到实践(第2版)》之三:静态网页抓取
点击查看第一章点击查看第二章 第3章 静态网页抓取在网站设计中,纯粹HTML格式的网页通常被称为静态网页,早期的网站一般都是由静态网页制作的。在网络爬虫中,静态网页的数据比较容易获取,因为所有数据都呈现在网页的 HTML代码中。相对而言,使用AJAX动态加载网页的数据不一定会出现在HTML代码中,这...
带你读《Python网络爬虫从入门到实践(第2版)》之二:编写第一个网络爬虫
点击查看第一章点击查看第三章 第2章 编写第一个网络爬虫 笔者是一个喜欢学习的人,自学了各方面的知识,总结发现:学习的动力来自于兴趣,兴趣则来自于动手做出成果的快乐。因此,笔者特意将动手的乐趣提前。在第2章,读者就可以体会到通过完成一个简单的Python网络爬虫而带来的乐趣。希望这份喜悦能让你继续学...
带你读《Python网络爬虫从入门到实践(第2版)》之一:网络爬虫入门
点击查看第二章点击查看第三章Python网络爬虫从入门到实践(第2版) 唐 松 编著 第1章 网络爬虫入门 网络爬虫就是自动地从互联网上获取程序。想必你听说过这个词汇,但是又不太了解,会觉得掌握网络爬虫还是要花一些工夫的,因此这个门槛让你有点望而却步。我常常觉得计算机和互联网的发明给人类带来了如此大...
Python 网络爬虫入门详解
什么是网络爬虫 网络爬虫又称网络蜘蛛,是指按照某种规则在网络上爬取所需内容的脚本程序。众所周知,每个网页通常包含其他网页的入口,网络爬虫则通过一个网址依次进入其他网址获取所需内容。 优先申明:我们使用的python编译环境为PyCharm 一、首...
PYTHON系列-从零开始的爬虫入门指南
入门0.准备工作 需要准备的东西: Python、scrapy、一个IDE或者随便什么文本编辑工具。 1.技术部已经研究决定了,你来写爬虫。 随便建一个工作目录,然后用命令行建立一个工程,工程名为miao,可以替换为你喜欢的名字。 1scrapy startproject miao 随后你会得到如下...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








Python爬虫入门相关内容
Python更多爬虫相关
- Python爬虫beautifulsoup
- Python爬虫程序
- Python爬虫策略
- 数据采集Python爬虫
- Python爬虫代理
- Python爬虫ip
- Python爬虫伪装
- Python爬虫代理ip
- Python爬虫商品
- Python爬虫爬取
- Python爬虫数据
- Python爬虫库
- Python爬虫实战
- Python爬虫抓取
- Python爬虫技术
- Python爬虫scrapy
- Python爬虫网页
- Python爬虫解析
- Python爬虫urllib
- Python爬虫数据抓取
- Python爬虫框架项目实战
- Python爬虫工具
- Python爬虫电影
- Python爬虫xpath
- Python爬虫请求
- Python爬虫百度
- Python爬虫app
- Python爬虫采集
- Python爬虫分析
- Python爬虫原理
- Python爬虫实例
- Python爬虫入门教程数据抓取
- Python爬虫文章
- Python爬虫请求头
- Python爬虫requests库
- Python爬虫线程
- Python爬虫验证码
- Python技术爬虫
- Python爬虫技术框架
- Python爬虫数据分析
- Python网络爬虫爬虫
- Python技术框架项目实战爬虫
- Python爬虫下载
- Python爬虫登录
- Python爬虫get
- Python爬虫csdn
- Python爬虫ajax
- Python爬虫微信
- Python爬虫基础
- Python爬虫入门教程图片爬取