
Python爬虫深度优化:Scrapy库的高级使用和调优
在我们前面的文章中,我们探索了如何使用Scrapy库创建一个基础的爬虫,了解了如何使用选择器和Item提取数据,以及如何使用Pipelines处理数据。在本篇高级教程中,我们将深入探讨如何优化和调整Scrapy爬虫的性能,以及如何处理更复杂的抓取任务,如登录,处理Cookies和会话,...

Python 爬虫(六): Scrapy的使用
Scrapy 是一个使用 Python 语言开发,为了爬取网站数据,提取结构性数据而编写的应用框架,它用途广泛,比如:数据挖掘、监测和自动化测试。安装使用终端命令 pip install Scrapy 即可。 Scrapy 比较吸引人的地方是:我们可以根据需求对其进行修改,它提供了多种类型的爬虫基类...


Python爬虫基础:使用Scrapy库初步探索
Scrapy是Python中最流行的网页爬虫框架之一,强大且功能丰富。通过Scrapy,你可以快速创建一个爬虫,高效地抓取和处理网络数据。在这篇文章中,我们将介绍如何使用Scrapy构建一个基础的爬虫。 一、Scrapy简介及安装 Scrapy是一个用Python实现的开源网页爬虫框架,主要用于网页...
聚焦Python分布式爬虫必学框架Scrapy打造搜索引擎
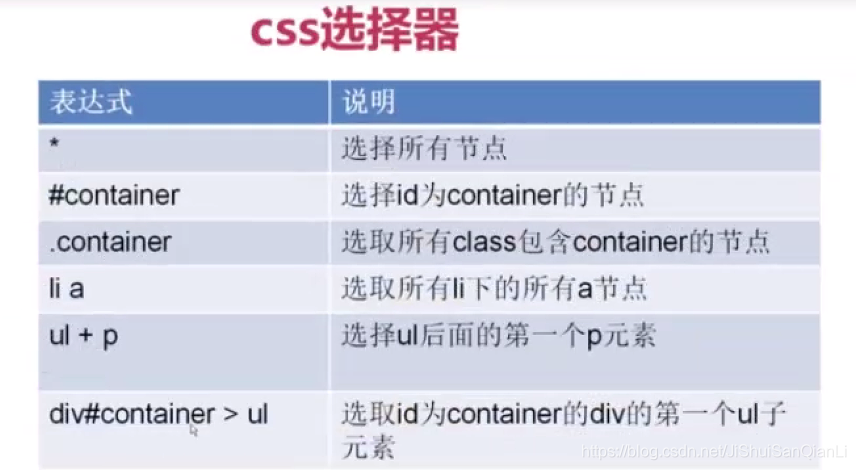
CSS选择器 XPath的用法一、选取节点常用的路劲表达式:表达式描述实例 nodename选取nodename节点的所有子节点xpath(‘//div’)选取了div节点的所有子节点/从根节点选取xpath(‘/div’)从根节点上选取di...
Python爬虫:scrapy内置网页解析库parsel-通过css和xpath解析xml、html
文档https://pypi.org/project/parsel/https://github.com/scrapy/parsel安装pip install parsel代码示例from parsel import Selector selector = Selector(text="""<...
Python爬虫:Scrapy优化参数设置
修改 settings.py 文件# 增加并发 CONCURRENT_REQUESTS = 100 # 降低log级别 LOG_LEVEL = 'INFO' # 禁止cookies COOKIES_ENABLED = False # 禁止重试 RETRY_ENABLED = Fa...
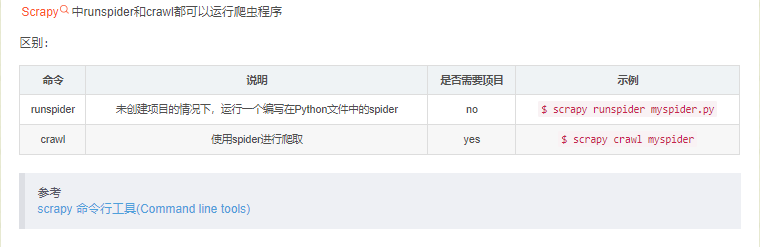
Python爬虫:Scrapy中runspider和crawl的区别
Python爬虫:Scrapy中runspider和crawl的区别
Python爬虫:Scrapy的Crawler对象及扩展Extensions和信号Signa
先了解Scrapy中的Crawler对象体系Crawler对象settings crawler的配置管理器set(name, value, priority=‘project’)setdict(values, priority=‘project’)setmodule(module, priority...
Python爬虫:scrapy辅助功能实用函数
scrapy辅助功能实用函数:get_response: 获得scrapy.HtmlResponse对象, 在不新建scrapy项目工程的情况下,使用scrapy的一些函数做测试extract_links: 解析出所有符合条件的链接代码示例以拉勾首页为例,获取拉勾首页所有职位链接,进一步可以单独解析...
Python爬虫:scrapy-splash的请求头和代理参数设置
3中方式任选一种即可1、lua中脚本设置代理和请求头:function main(splash, args) -- 设置代理 splash:on_request(function(request) request:set_proxy{ host = "27.0.0.1", p...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








Python爬虫scrapy相关内容
Python更多爬虫相关
- Python爬虫beautifulsoup
- Python爬虫程序
- Python爬虫策略
- 数据采集Python爬虫
- Python爬虫代理
- Python爬虫ip
- Python爬虫伪装
- Python爬虫代理ip
- Python爬虫商品
- Python爬虫爬取
- Python爬虫数据
- Python爬虫库
- Python爬虫实战
- Python爬虫抓取
- Python爬虫技术
- Python爬虫入门
- Python爬虫网页
- Python爬虫解析
- Python爬虫入门教程
- Python爬虫urllib
- Python爬虫数据抓取
- Python爬虫框架项目实战
- Python爬虫工具
- Python爬虫入门教程爬取
- Python爬虫电影
- Python爬虫xpath
- Python爬虫请求
- Python爬虫百度
- Python爬虫app
- Python爬虫采集
- Python爬虫分析
- Python爬虫原理
- Python爬虫实例
- Python爬虫入门教程数据抓取
- Python爬虫文章
- Python爬虫请求头
- Python爬虫requests库
- Python爬虫线程
- Python爬虫验证码
- Python技术爬虫
- Python爬虫技术框架
- Python爬虫数据分析
- Python网络爬虫爬虫
- Python技术框架项目实战爬虫
- Python爬虫下载
- Python爬虫登录
- Python爬虫get
- Python爬虫csdn
- Python爬虫ajax
- Python爬虫微信