
Python爬虫案例:抓取猫眼电影排行榜
抓取猫眼电影排行 本节中,我们利用 requests 库和正则表达式来抓取猫眼电影 TOP100 的相关内容。requests 比 urllib 使用更加方便,而且目前我们还没有系统学习 HTML 解析库,所以这里就选用正则表达式来作为解析工具。 同时我会放出Xpath和Beautiful Soup...
Python爬虫抓取经过JS加密的API数据的实现步骤
随着互联网的快速发展,越来越多的网站和应用程序提供了API接口,方便开发者获取数据。然而,为了保护数据的安全性和防止漏洞,一些API接口采用了JS加密技术这种加密技术使得数据在传输过程中更加安全,但也给爬虫开发带来了一定的难度。。在面对经过JS加密的API数据时,我们需要分析加密算法和参数,以便我们...

Python爬虫与逆向工程技术的结合,实现新闻网站动态内容的多线程抓取
嗨,亲爱的python小伙伴们,大家都知道Python爬虫是一种强大的工具,可以帮助我们从网页中提取所需的信息。然而,有时候我们需要从新闻网站抓取动态内容,但是有些新闻网站使用了动态内容加载技术使得传统的爬虫方法无法获取完整的新闻内容。在这种情况下,我们可以借助逆向工程技术,结合多线程抓取的方式&a...
无人驾驶车辆中Python爬虫的抓取与决策算法研究
无人驾驶车辆(Autonomous Vehicles)是当今科技领域的一项重要创新,它代表了人工智能和自动化技术的巅峰结合。无人驾驶车辆的出现引发了全球范围内的关注和研究,其潜力和影响力不可忽视。本文将深入探讨无人驾驶车辆的技术原理、挑战和前景。无人驾驶车辆的原理基于先进的感知和决策系统。感知系统包...
Python爬虫抓取网页
本节讲解第一个 Python 爬虫实战案例:抓取您想要的网页,并将其保存至本地计算机。 首先我们对要编写的爬虫程序进行简单地分析,该程序可分为以下三个部分: 拼接 url 地址发送请求将照片保存至本地明确逻辑后,我们就可以正式编写爬虫程序了。 导入所需模块本节内容使用 urllib 库来编写爬虫,下...
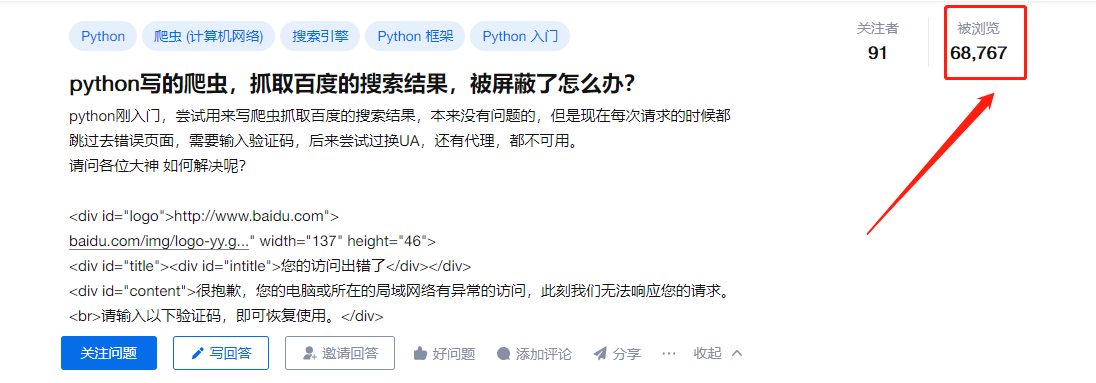
python写的爬虫,抓取百度的搜索结果,被屏蔽了怎么办?
某乎上有个热门话题,引起了很大的讨论。这个问题通常是由于频繁的请求导致百度的反爬虫机制触发了验证码的保护机制。解决办法无非是那几套流程走一遍。1.增加请求的时间间隔通过在每个请求之间增加一些时间间隔,可以降低请求频率,从而避免被反爬虫机制检测到。例如,可以使用time模块中的sleep函数在每个请求...
Python爬虫通过selenium自动化抓取淘宝的商品数据
淘宝的页面大量使用了js加载数据,所以采用selenium来进行爬取更为简单,selenum作为一个测试工具,主要配合无窗口浏览器phantomjs来使用。完整代码import re from selenium import webdriver from selenium.common.except...
Python爬虫系列17-批量抓取某短视频平台某用户的全部作品
实战第一步:请求网络;获取到网站返回的数据内容 import requests cookies = { 'did': 'web_87ee5530f7dc26c5c05dfe66acf70e14', 'didv': '1649420428219', 'kpf': 'PC_WEB', 'kpn': 'K...

Python爬虫系列9-非诚勿扰等婚恋网数据批量抓取!
-实战今天要采集的网站是 https://www.baihe.com/home.shtml第一步:分析目标网站,找到需要抓取的内容,请求网页点击每一个相亲妹子后会进入详情页,我先将需要抓取的数据字段标注出来;好了;以上就是我们接下来要抓取的字段;通过F12【抓包工具】分析网页结构,进行数据请求 经过...

Python爬虫系列8-抓取快乐8、刮刮乐、双色球等中奖数据分析规律
-实战这几天看到身边的朋友在玩儿股票;顺便查了查彩票的官网及操作步骤;看到那些以往的中奖号码; 脑海中突然有个新的想法;如果我把中奖的号码全部都抓取下来;在通过数据分析进行可视化;分析那些出现频率高的中奖数字。会不会有奇效呢!想的再多 不如尝试一下。目标网站快乐8 彩球数据这些都是中奖的号码;大家可...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








Python更多爬虫相关
- Python爬虫beautifulsoup
- Python爬虫程序
- Python爬虫策略
- 数据采集Python爬虫
- Python爬虫代理
- Python爬虫ip
- Python爬虫伪装
- Python爬虫代理ip
- Python爬虫商品
- Python爬虫爬取
- Python爬虫数据
- Python爬虫库
- Python爬虫实战
- Python爬虫技术
- Python爬虫scrapy
- Python爬虫入门
- Python爬虫网页
- Python爬虫解析
- Python爬虫入门教程
- Python爬虫urllib
- Python爬虫数据抓取
- Python爬虫框架项目实战
- Python爬虫工具
- Python爬虫入门教程爬取
- Python爬虫电影
- Python爬虫xpath
- Python爬虫请求
- Python爬虫百度
- Python爬虫app
- Python爬虫采集
- Python爬虫分析
- Python爬虫原理
- Python爬虫实例
- Python爬虫入门教程数据抓取
- Python爬虫文章
- Python爬虫请求头
- Python爬虫requests库
- Python爬虫线程
- Python爬虫验证码
- Python技术爬虫
- Python爬虫数据分析
- Python技术框架项目实战爬虫
- Python爬虫下载
- Python爬虫登录
- Python爬虫get
- Python爬虫csdn
- Python爬虫ajax
- Python爬虫微信
- Python爬虫基础
- Python爬虫入门教程图片爬取