使用UDF扩展Spark SQL
Apache Spark是一个强大的分布式计算框架,Spark SQL是其一个核心模块,用于处理结构化数据。虽然Spark SQL内置了许多强大的函数和操作,但有时可能需要自定义函数来处理特定的数据需求。在Spark SQL中,可以使用UDF(User-Defined Functions)来自定义函...
[帮助文档] 如何在Spark中管理并使用用户自定义函数UDF
本文档主要介绍了如何在Spark中管理并使用用户自定义函数UDF(User Define Function)。


Note_Spark_Day08:Spark SQL(Dataset是什么、外部数据源、UDF定义和分布式SQL引擎)
Note_Spark_Day08:Spark SQL(Dataset是什么、外部数据源、UDF定义和分布式SQL引擎)
MaxCompute里spark 里面有支持访问 udf 函数的计划吗?
spark 里面有支持访问 udf 函数的计划吗?在spark sql中使用collect_list within group
spark 里面有支持访问 udf 函数的计划吗?
spark 里面有支持访问 udf 函数的计划吗?在spark sql中使用collect_list within group
MaxCompute中Logview如何查看UDF或Spark任务打印的日志
MaxCompute中Logview如何查看UDF或Spark任务打印的日志
SPARK 3.1.2 Driver端下载UDF jar包导致磁盘爆满
背景本文基于spark 3.1.2且配置 spark.sql.catalogImplementation=hive在以spark-sql形式运行sql任务时,发现运行driver端的机器的磁盘总是会达到95%以上的利用率,这样在夜生人静的时候,总会有电话来问候。分析经过分析,我们发现是/tmp/${...
Spark的UDF是什么?
Spark的UDF是什么?
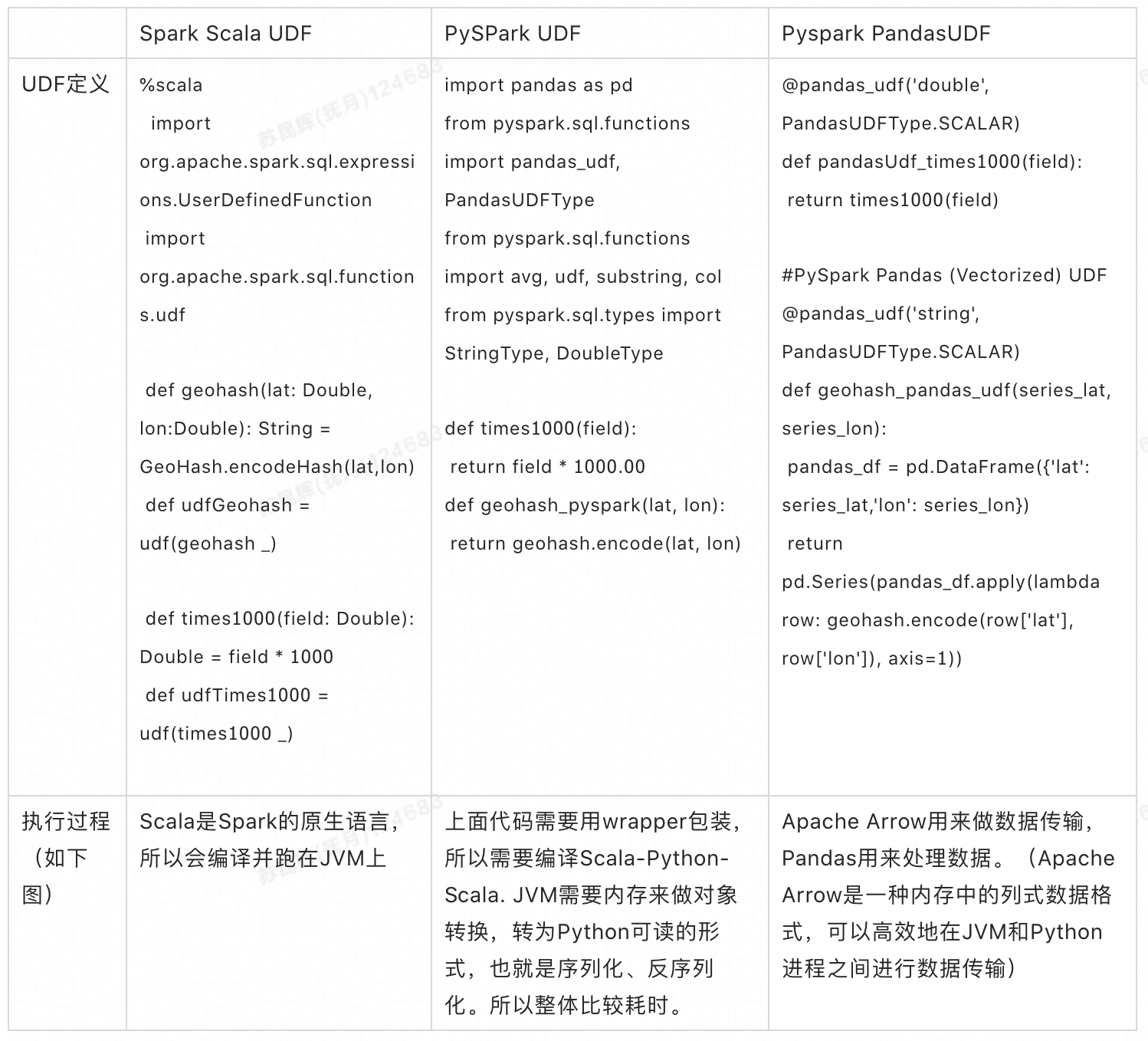
【译】深入分析Spark UDF的性能
原文链接 https://medium.com/@QuantumBlack/spark-udf-deep-insights-in-performance-f0a95a4d8c62 编译:抚月,阿里巴巴计算平台事业部 EMR 高级工程师,Apache HDFS Committer,目前从事开...
请问spark的udf中能不能设置异步操作内容 ?
请问spark的udf中能不能设置异步操作内容? 比如根据当前列的值查询neo4j 本问题来自阿里云开发者社区的【11大垂直技术领域开发者社群】。https://developer.aliyun.com/article/706511 点击链接欢迎加入感兴趣的技术领域群。
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark您可能感兴趣
- apache spark深度学习
- apache spark资源消耗
- apache spark资源
- apache spark优缺点
- apache spark机器学习
- apache spark内存
- apache spark大规模
- apache spark分析
- apache spark引擎
- apache spark数据处理
- apache spark SQL
- apache spark streaming
- apache spark Apache
- apache spark数据
- apache spark rdd
- apache spark Hadoop
- apache spark大数据
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark大数据分析