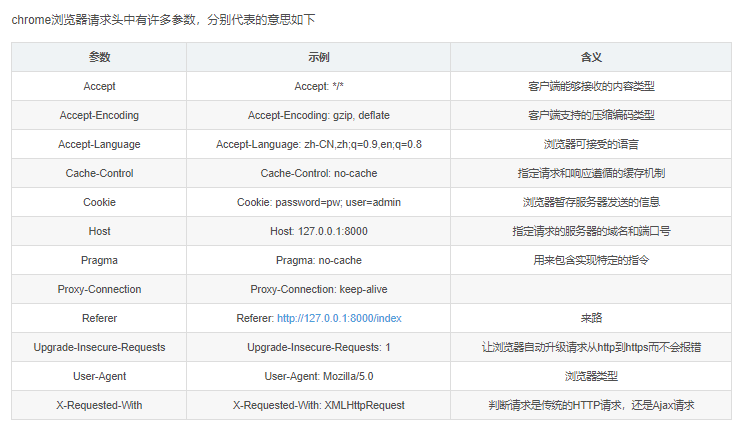
Python爬虫:浏览器请求头参数RequestHeaders
Python爬虫:浏览器请求头参数RequestHeaders
Python爬虫:使用httpbin.org测试爬虫请求头信息
一般程序写的爬虫程序都会自带请求头,不知不觉就被网站拒绝了,请求之前可以看看自己的请求头是什么,确保不被禁地址:https://httpbin.org/如果网站太慢打不开,想在本地搭建测试环境,可以在docker环境下启动:$ docker run -p 80:80 kennethreitz/htt...

Python爬虫:scrapy-splash的请求头和代理参数设置
3中方式任选一种即可1、lua中脚本设置代理和请求头:function main(splash, args) -- 设置代理 splash:on_request(function(request) request:set_proxy{ host = "27.0.0.1", p...
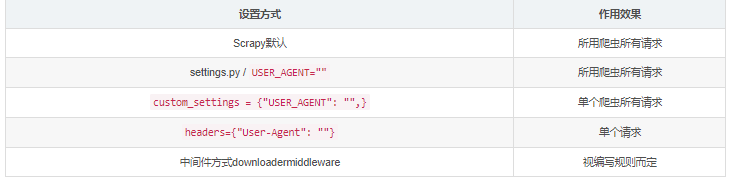
Python爬虫:关于scrapy模块的请求头
内容简介使用scrapy写爬虫的时候,会莫名其妙的被目标网站拒绝,很大部分是浏览器请求头的原因。现在一起来看看scrapy的请求头,并探究设置方式工具准备开发环境python2.7 + scrapy 1.1.2测试请求头网站:https://httpbin.org/get?show_env=1jso...
Python爬虫:常用的user_agent请求头
user_agent = [“Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50”,“Mozilla/5.0...
Python爬虫:fake_useragent库模拟浏览器请求头
简单示例# -*- coding: utf-8 -*- # @File : fake_useragent_demo.py # @Date : 2018-05-28 from fake_useragent import UserAgent ua = UserAgent() print(ua.ie) p...
Python爬虫:将headers请求头字符串转为字典
原生请求头字符串raw_headers = """Host: open.tool.hexun.com Pragma: no-cache Cache-Control: no-cache User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2...
Python爬虫:常用的浏览器请求头User-Agent
user_agent = [ "Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50", "Mozilla/5...
Python - 爬虫中文乱码之请求头 Accept-Encoding Brotli 问题
当用 Python3 做爬虫的时候,一些网站为了防爬虫会设置一些检查机制,这时我们就需要添加请求头,伪装成浏览器正常访问。header的内容在浏览器的开发者工具中便可看到,将这些信息添加到我们的爬虫代码中即可。Accept-Encoding:是浏览器发给服务器,声明浏览器支持的编码类型。一般有 gz...
python爬虫设置请求头headers
使用python写爬虫的时候,通常要设置请求头。 以使用requests库访问百度为例,代码如下: import requests headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








Python爬虫相关内容
- Python爬虫beautifulsoup
- Python爬虫程序
- Python爬虫策略
- 数据采集Python爬虫
- Python爬虫代理
- Python爬虫ip
- Python爬虫伪装
- Python爬虫代理ip
- Python爬虫商品
- Python爬虫京东
- Python爬虫appium
- Python爬虫app
- Python爬虫微信朋友圈
- Python爬虫爬取
- Python爬虫微信
- Python爬虫爬取微信
- Python爬虫mitmproxy
- Python爬虫charles
- Python爬虫cookies
- Python爬虫登录
- Python爬虫github
- Python爬虫文章
- Python爬虫付费
- Python爬虫代理池
- Python爬虫原理
- Python爬虫验证码识别
- Python爬虫验证码
- Python爬虫滑动验证
- Python爬虫项目
- Python爬虫实例
- Python爬虫请求
- Python爬虫技术
- Python爬虫工具
- Python爬虫数据
- Python爬虫实战
- Python爬虫数据爬取
- Python爬虫agent
- Python web爬虫
- Python爬虫分析
- Python爬虫数据采集分析
- Python爬虫数据采集
- Python爬虫实战多多商品数据分析
- Python爬虫数据分析
- Python爬虫splash
- Python爬虫源码
- Python爬虫源码总有
- Python爬虫数据抓取
- Python爬虫实战分析
- Python爬虫网页
Python更多爬虫相关
- Python爬虫库
- Python爬虫抓取
- Python爬虫scrapy
- Python爬虫入门
- Python爬虫解析
- Python爬虫入门教程
- Python爬虫urllib
- Python爬虫框架项目实战
- Python爬虫入门教程爬取
- Python爬虫电影
- Python爬虫xpath
- Python爬虫百度
- Python爬虫采集
- Python爬虫入门教程数据抓取
- Python爬虫requests库
- Python爬虫线程
- Python技术爬虫
- Python爬虫技术框架
- Python技术框架项目实战爬虫
- Python爬虫下载
- Python爬虫get
- Python爬虫csdn
- Python爬虫ajax
- Python爬虫基础
- Python爬虫入门教程图片爬取
- Python爬虫入门教程图片
- Python爬虫报错
- Python爬虫数据库
- Python爬虫入门教程scrapy
- Python爬虫post
- Python爬虫解析网页
- Python爬虫get请求
- Python爬虫区别
- Python爬虫功能
- Python爬虫scrapy设置
- Python爬虫beautifulsoup4
- Python爬虫学习
- Python爬虫入门教程数据scrapy
- Python爬虫进程
- Python爬虫网站
- Python爬虫基本原理
- Python爬虫Scrapy框架
- Python爬虫页面
- Python爬虫入门教程技术
- Python网络爬虫selenium
- Python爬虫http
- Python爬虫豆瓣电影
- Python爬虫分布式
- Python爬虫入门教程多线程爬取
- Python爬虫beautifulsoup解析