Python爬虫在Django项目中的数据处理与展示实例
当谈到Python爬虫技术与Django项目结合时,我们面临着一个引人入胜又具有挑战性的任务——如何利用爬虫技术从网络上抓取数据,并将这些数据进行有效地处理和展示。在本文中,我将为您介绍Python爬虫技术在Django项目中的数据抓取与处理流程。在开始之前,我们先明确一下Python爬虫技术的基本...
Python小知识 - 一个简单的Python爬虫实例
一个简单的Python爬虫实例这是一个简单的Python爬虫实例,我们将使用urllib库来下载一个网页并解析它。首先,我们需要安装urllib库:pip install urllib 接下来,我们来看看如何使用urllib库来下载一个网页: import urllib.request 这是要下载的...

python 爬虫 佛山区域,爬取餐厅的商户联系人公开号码,实例脚本
佛山区域,爬取餐厅的商户联系人公开号码 导入requests库 import requests 设置请求参数 key = "你的高德key" city = "佛山" types = "餐饮服务" offset = 20 # 每页返回结果数,最大值为25 page = 1 # 当前页数ÿ...
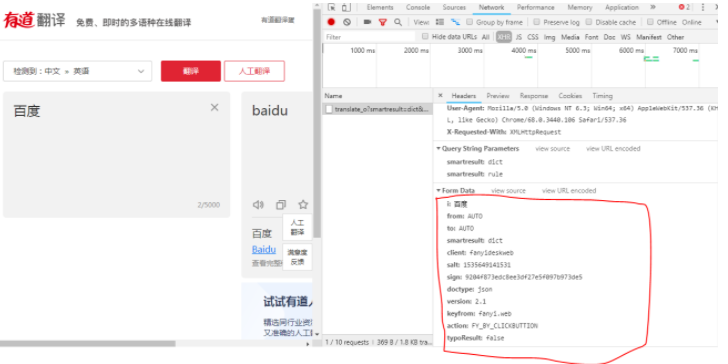
Python爬虫:js加密实例-有道翻译
实现步骤1、随便输入关键字,打开调试,发现是ajax传输,post请求不难发现,请求连接Request URL:http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule里边有我们需要的json数据{ "tran...

10个经典Python爬虫入门实例!你还不知道吗
伙伴们学习python爬虫,准备了几个简单的入门实例,分享给大家。代码中给出了注释,并且可以直接运行哦如何安装requests库(安装好python的朋友可以直接参考,没有的,建议先装一哈python环境)windows用户,Linux用户几乎一样:打开cmd输入以下命令即可,如果python的环境...

python编程-21:最简单的网络爬虫5个实例
1、爬取京东商城页面2、爬取亚马逊商城页面3、向百度和360搜索引擎提交关键词4、下载国家地理杂志图片到本地5.IP地址查询
【资料下载】Python 第十讲——xpath元素定位获取及爬虫中使用实例
直播时间:4月2日 20:00——21:00 直播介绍:python是非常适合敏捷开发的语言,用python编写爬虫快速获取数据,并做数据分析,对日常生活和工作能起到一定帮助。而python爬虫有很多种爬取方式,例如Requests+正则表达式、selenium+Chrome/PhantomJS等,...
Python微博移动端爬虫实例(附代码)
本文简要讲述用Python爬取微博移动端数据的方法。可以看一下Robots协议。另外尽量不要爬取太快。如果你毫无节制的去爬取别人数据,别人网站当然会反爬越来越严厉。至于为什么不爬PC端,原因是移动端较简单,很适合爬虫新手入门。有时间再写PC端吧! 环境介绍 Python3/Windows-10-64...
Python---BeautifulSoup 简单的爬虫实例
对python自动化比较熟的同学,很多都懂一些爬虫方法,有些还研究的很深,下面呢我介 绍一个简单的爬虫实例,供大家参考。当然里面有很多需求是可以再学习的,下载进度的显 示、下载完成的提示等等。 一、首先我们要研究爬虫网站的架构,我这里已ring.itools...
python爬虫从入门到放弃(九)之 实例爬取上海高级人民法院网开庭公告数据
通过前面的文章已经学习了基本的爬虫知识,通过这个例子进行一下练习,毕竟前面文章的知识点只是一个 一个单独的散知识点,需要通过实际的例子进行融合 分析网站 其实爬虫最重要的是前面的分析网站,只有对要爬取的数据页面分析清楚,才能更方便后面爬取数据 目标站和目标数据目标地址:http://www.hshf...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








Python爬虫相关内容
- 数据采集Python爬虫
- Python爬虫代理
- Python爬虫ip
- Python爬虫伪装
- Python爬虫代理ip
- Python爬虫商品
- Python爬虫京东
- Python爬虫appium
- Python爬虫app
- Python爬虫微信朋友圈
- Python爬虫爬取
- Python爬虫微信
- Python爬虫爬取微信
- Python爬虫mitmproxy
- Python爬虫charles
- Python爬虫cookies
- Python爬虫登录
- Python爬虫github
- Python爬虫文章
- Python爬虫付费
- Python爬虫代理池
- Python爬虫原理
- Python爬虫验证码识别
- Python爬虫验证码
- Python爬虫滑动验证
- Python爬虫项目
- Python爬虫请求
- Python爬虫技术
- Python爬虫agent
- Python web爬虫
- Python爬虫实战
- Python爬虫分析
- Python爬虫数据采集分析
- Python爬虫数据采集
- Python爬虫实战多多商品数据分析
- Python爬虫数据分析
- Python爬虫数据
- Python爬虫splash
- Python爬虫源码
- Python爬虫源码总有
- Python爬虫数据抓取
- Python爬虫实战分析
- Python爬虫网页
- Python爬虫自动化
- Python爬虫测试
- Python爬虫自动化测试
- Python爬虫工具
- Python爬虫ajax
Python更多爬虫相关
- Python爬虫库
- Python爬虫抓取
- Python爬虫scrapy
- Python爬虫解析
- Python爬虫入门教程
- Python爬虫beautifulsoup
- Python爬虫urllib
- Python爬虫框架项目实战
- Python爬虫入门
- Python爬虫入门教程爬取
- Python爬虫电影
- Python爬虫xpath
- Python爬虫百度
- Python爬虫采集
- Python爬虫入门教程数据抓取
- Python爬虫请求头
- Python爬虫requests库
- Python爬虫线程
- Python技术爬虫
- Python技术框架项目实战爬虫
- Python爬虫下载
- Python爬虫get
- Python爬虫csdn
- Python爬虫基础
- Python爬虫入门教程图片爬取
- Python爬虫入门教程图片
- Python爬虫报错
- Python爬虫数据库
- Python爬虫入门教程scrapy
- Python爬虫post
- Python爬虫解析网页
- Python爬虫get请求
- Python爬虫区别
- Python爬虫功能
- Python爬虫scrapy设置
- Python爬虫beautifulsoup4
- Python爬虫学习
- Python爬虫入门教程数据scrapy
- Python爬虫进程
- Python爬虫网站
- Python爬虫基本原理
- Python爬虫Scrapy框架
- Python爬虫页面
- Python爬虫入门教程技术
- Python网络爬虫selenium
- Python爬虫http
- Python爬虫数据爬取
- Python爬虫豆瓣电影
- Python爬虫分布式
- Python爬虫入门教程多线程爬取