

[帮助文档] 调用SetSparkAppLogRootPath更改用户Spark的日志配置
更改用户Spark的日志配置。
大数据计算MaxCompute Spark Local 模式启动报错,还需要开其他的配置么?
大数据计算MaxCompute Spark Local 模式启动报错,查了这个AK是有odps:权限的,还需要开其他的配置么?Exception in thread "main" java.util.concurrent.ExecutionException: [403] com.aliyun.od...

DataWorks如果 odps中spark请求一个内网地址如何配置这个呢 在config中配置么?
DataWorks中SET odps.session.networklink = Maxcomputer_boldvpc 如果 odps中spark请求一个内网地址 如何配置这个呢 在config中配置么?
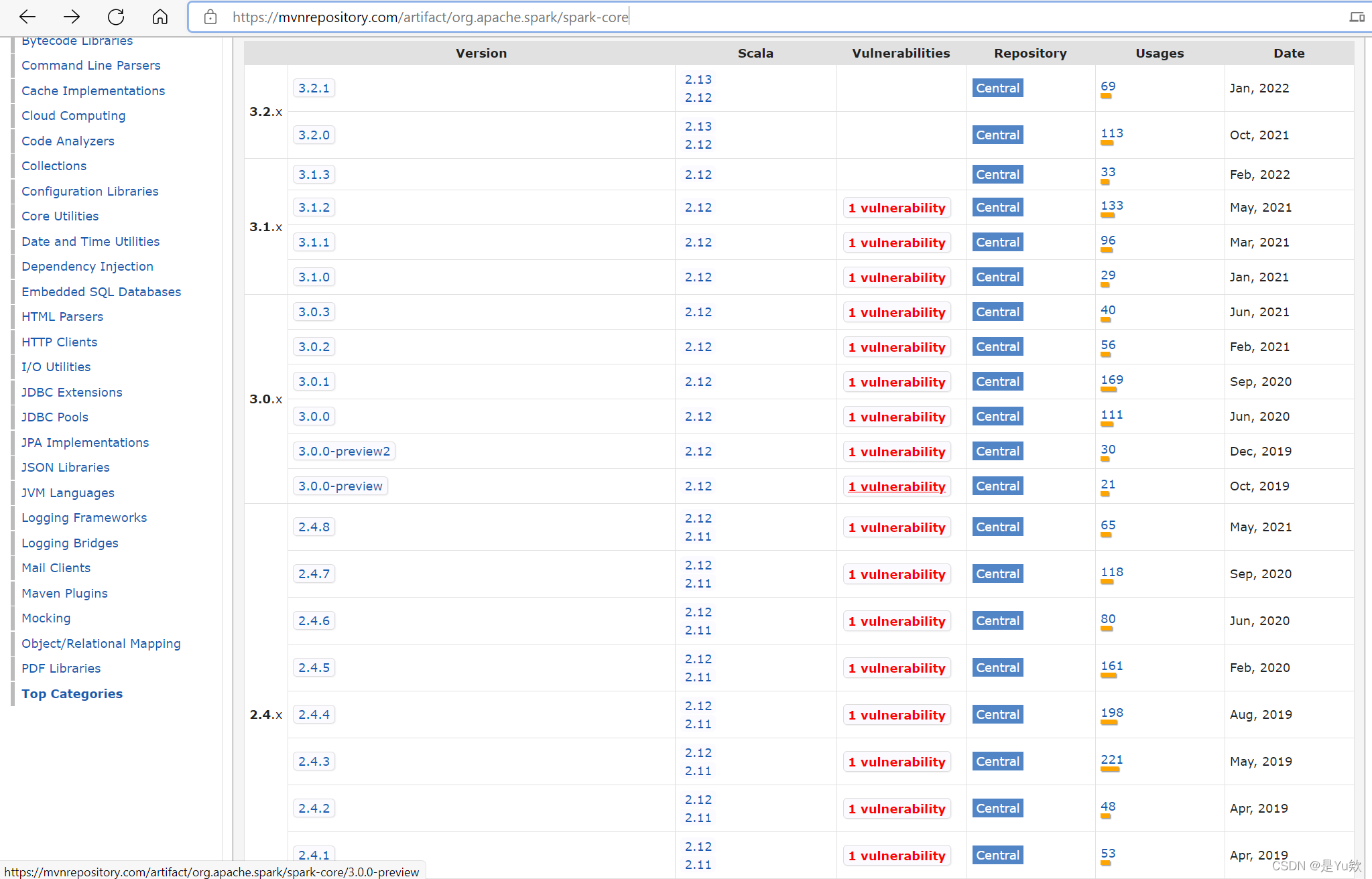
配置spark,并在idea中搭建项目
网上的普遍太久远,不太适配,记录自己的完美搭建一、配置spark1.配置maven(注意选择版本为3.6.3)参考:https://blog.csdn.net/huo920/article/details/82082403但这一步是多余的2.下载scala(注意版本对应为2.12)查看scala版本...
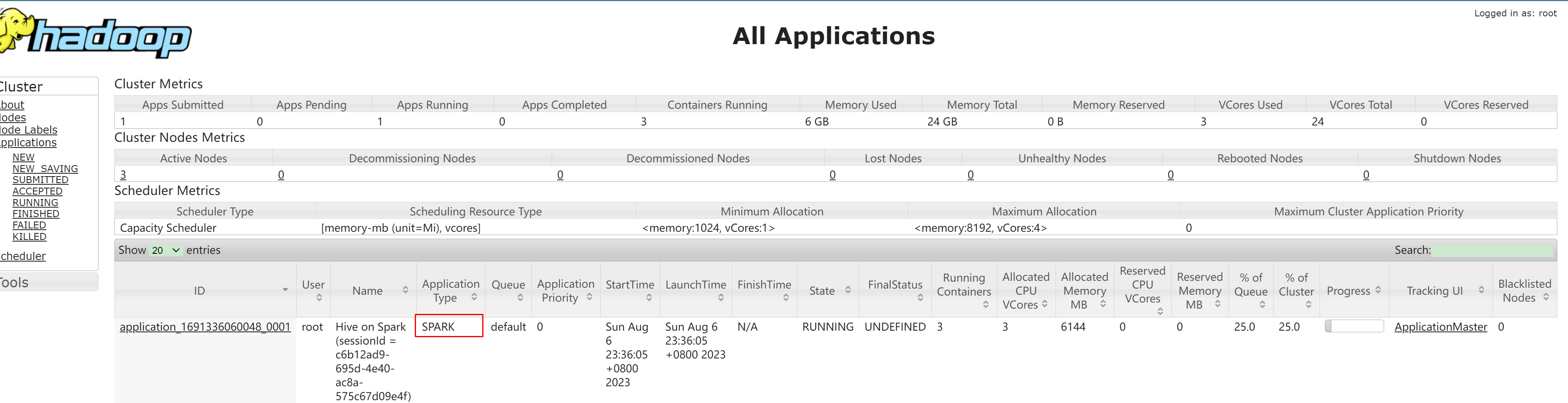
配置Hive使用Spark执行引擎
Hive引擎 概述 在Hive中,可以通过配置来指定使用不同的执行引擎。Hive执行引擎包括:默认MR、tez、spark MapReduce引擎: 早期版本Hive使用MapReduce作为执行引擎。MapReduce是Hadoop的一种计算模型,它通过将数据划分为小块并在集群上并行处理来完成计算...
DataWorks odps spark 日志中文输出乱码?这个配置没作用
DataWorks odps spark 日志中文输出乱码?这个配置没作用
dataworks里的spark程序连接数据源,需要开通或者配置什么?
dataworks里的spark程序连接数据源,需要开通或者配置什么?
DataWorks中Local 方式使用 Spark 配置好jar包,依旧报The value ?
DataWorks中Local 方式使用 Spark 配置好jar包,依旧报The value of spark.sql.catalogImplementation should be one of hive, in-memory, but was odps?

Spark SQL CLI配置
Spark SQL CLI配置 SparkSQL可以兼容Hive以便SparkSQL支持Hive表访问、UDF(用户自定义函数)以及Hive查询语言(HiveQL/HQL)。若要使用SparkSQLCLI的方式访问操作Hive表数据,需要对SparkSQL进行如下所示的环境配置(Spark集群已搭建...
dataworks里面执行spark sql, 报没有oss 403权限问题。 但是,配置的?
dataworks里面执行spark sql, 报没有oss 403权限问题。 但是,配置的oss数据源已经又对应bucket完全控制权限? bucket授权是完全控制
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark配置相关内容
apache spark您可能感兴趣
- apache spark分布式
- apache spark Hadoop
- apache spark Python
- apache spark大数据技术
- apache spark算子
- apache spark动作
- apache spark hudi
- apache spark集成
- apache spark cdc
- apache spark flink
- apache spark SQL
- apache spark streaming
- apache spark Apache
- apache spark数据
- apache spark rdd
- apache spark大数据
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark分析
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark程序
- apache spark操作