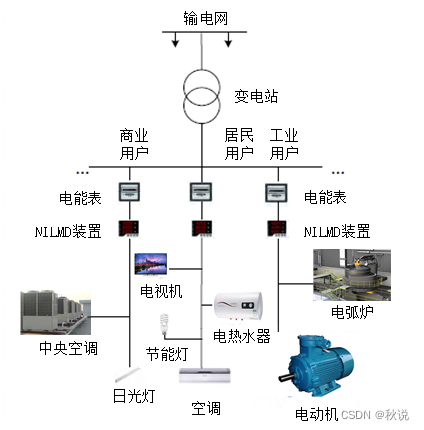
【Python数据挖掘】优化电能能源策略:基于非侵入式负荷检测与分解的智能解决方案
Python数据挖掘可以从大量的数据中提取有价值的信息和模式,进而帮助我们做出更明智的决策。本案例根据已收集到的电力数据,深度挖掘各电力设备的电流、电压和功率等情况,分析各电力设备的实际用电量,进而为电力公司制定电能能源策略提供一定的参考依据。案例背景为了更好地监测用电设备的能耗情况,电力分项计量技...

Python数据挖掘项目实战——自动售货机销售数据分析
01 案例背景近年来,随着我国经济技术的不断提升,自动化机械在人们日常生活中扮演着越来越重要的角色,更多的被应用在不同的领域。而作为新的一种自动化零售业态,自动售货机在日常生活中应用越来越广泛。自动售货机销售产业在走向信息化、合理化同时,也面临着高度同质化、成本上升、毛利下降等诸多困难与问题,这也是...

【Python百宝箱】数据科学的黄金三角:数据挖掘和聚类
数据之舞:Python数据科学库横扫全场前言在当今数据驱动的时代,Python成为数据科学家和分析师的首选工具之一。本文将介绍一系列强大的Python库,涵盖了数据处理、可视化、机器学习和自然语言处理等领域。无论你是初学者还是经验丰富的数据科学从业者,这些工具都能助你在数据探索和建模中事半功倍。 欢...

【Python数据挖掘】数据可视化及数据对象的相似性度量算法详解(超详细 附源码)
需要PPT和源码请点赞关注收藏后评论区留言私信~~~一、数据可视化数据可视化(Data Visualization)通过图形清晰有效地表达数据。它将数据所包含的信息的综合体,包括属性和变量,抽象化为一些图表形式。数据可视化方法包括:基于像素的技术几何投影技术基于图符的技术和基于图形的技术几何投影技术...
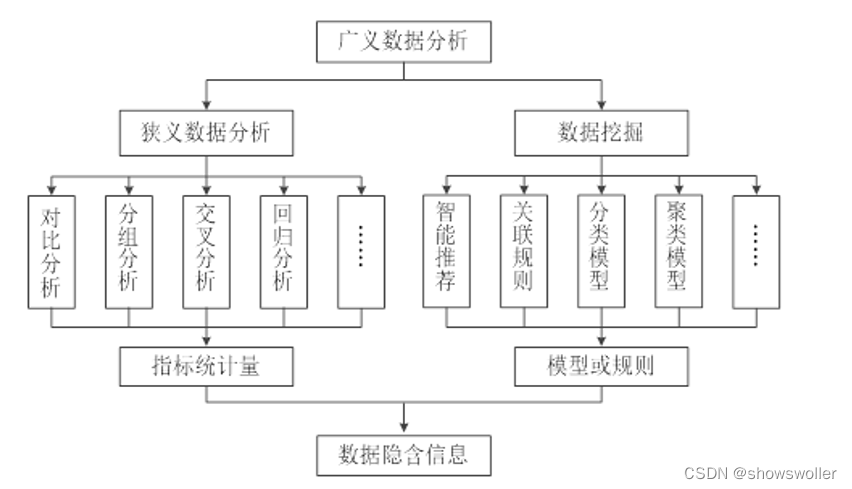
【Python数据挖掘】数据挖掘简介及Jupyter notebook操作介绍(图文解释 超详细)
需要完整PPT请点赞关注收藏后评论区留言并且私信~~~一、数据挖掘简介面对大量的数据,迫使人们不断寻找新的工具,对规律进行探索,为决策提供有价值的信息。数据挖掘有助于发现趋势,揭示已知的事实,预测未知的结果。 人们迫切希望能够对海量数据进行分析挖掘,发现并提取隐含在数据中的有价值信息。数据挖掘(Da...
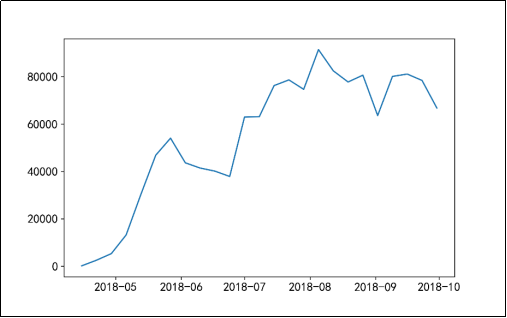
Python数据挖掘实用案例——自动售货机销售数据分析与应用(三)
2.平稳性检验 在使用ARIMA模型进行销售额预测之前,需要查看时间序列是否平稳,若数据非平稳,在数据分析挖掘的时候,则可能会产生“伪回归”等问题,从而影响分析结果。通过时间序列的时序图、自相关图及其单位根查看时间序列平稳性,时序图如图16所示,自相关图如图17所示,单位根检验结果如...
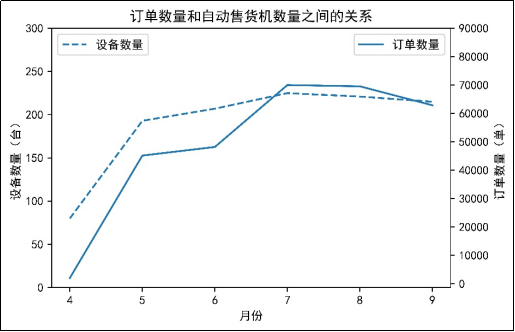
Python数据挖掘实用案例——自动售货机销售数据分析与应用(二)
2.订单数量和自动售货机数量的关系探索6个月订单数量和自动售货机数量之间的关系,并按时间走势进行可视化分析,结果如图6所示。 &nbs...

Python数据挖掘实用案例——自动售货机销售数据分析与应用(一)
一、前言 本文将主要结合自动售货机的实际情况,对销售的历史数据进行处理,利用pyecharts库、Matplotlib库进行可视化分析,并对未来4周商品的销售额进行预测,从而为企业制定相应的自动售货机市场需求分析及销售建议提供参考依据。更多详细内容请参考《Python数据挖掘:入门进阶与实用案例分...

数据挖掘:Python数据分析中的高级技术点
数据挖掘是从大量数据中发现有用信息和模式的过程。在当今数字化时代,数据不断产生和积累,数据挖掘成为了获取有价值洞察力的重要手段之一。Python作为一种功能强大的编程语言,在数据挖掘领域拥有广泛的应用。本文将介绍Python数据分析中的高级技术点,帮助您更深入地了解数据挖掘的过程和方法。 1. 特征...
Python数据分析与数据挖掘:解析数据的力量
引言:随着大数据时代的到来,数据分析和数据挖掘已经成为许多行业中不可或缺的一部分。在这个信息爆炸的时代,如何从大量的数据中提取有价值的信息,成为了企业和个人追求的目标。而Python作为一种强大的编程语言,提供了丰富的库和工具,使得数据分析和数据挖掘变得更加简单和高效。本文将深入探讨Python在数...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。

