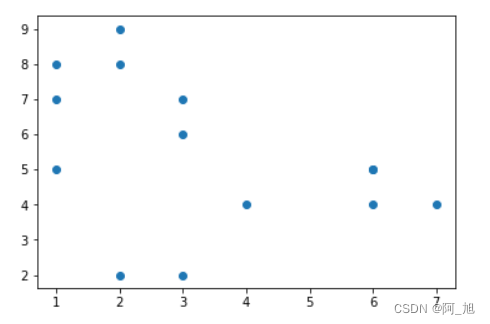
【阿旭机器学习实战】【17】KMeans聚类算法中如何选择合适的聚类个数K
KMeans聚类算法中如何选择合适的聚类个数?问题描述我们随机生成一些二维点的数据,然后通过不同的K值对其进行分类评估。具体步骤:随机生成一些二维点选取不同的K值进行模型训练,并计算轮廓系数画出K值与轮廓关系的折线图,看取哪一个K值合适1. 随机生成二维数据点import numpy as npx1...
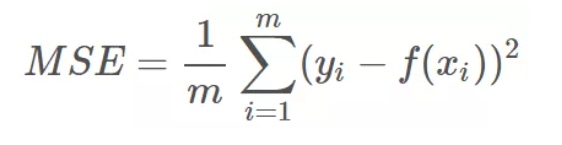
机器学习大牛是如何选择回归损失函数的?
无论在机器学习还是深度领域中,损失函数都是一个非常重要的知识点。损失函数(Loss Function)是用来估量模型的预测值 f(x) 与真实值 y 的不一致程度。我们的目标就是最小化损失函数,让 f(x) 与 y 尽量接近。通常可以使用梯度下降算法寻找函数最小值。关于梯度下降最直白的解释可以看我的...

Py之scikit-learn:机器学习Sklearn库的简介、安装、使用方法(ML算法如何选择)、代码实现之详细攻略
scikit-learn的简介 Scikit-learn项目最早由数据科学家 David Cournapeau 在 2007 年发起,需要NumPy和SciPy等其他包的支持,是Python语言中专门针对机器学习应用而发展起来的一款开源框架。 ...
如何选择开源的机器学习框架?
开源是创新和科技快速发展的核心。在此,我们将讨论如何针对不同的用例选取开源的机器学习工具。尽管机器学习还处于早期发展阶段,但从医疗、安全到个性化营销,这种潜在的价值使得公司将机器学习作为一种机会。 为什么要选择机器学习框架呢? 使用开源工具的好处不仅仅在于其可用性。通常来说,如此级别的项目均有大量的...
面对数据缺失,如何选择合适的机器学习模型?
本文来自AI新媒体量子位(QbitAI) 有些小伙伴在实际使用中发现xgboost可以自动处理缺失值,而有些模型不可以。我想先从两个角度解答这个困惑: 工具包自动处理数据缺失不代表具体的算法可以处理缺失项 对于有缺失的数据:以决策树为原型的模型优于依赖距离度量的模型 回答中也会介绍树模型,如随机森林...
机器学习如何选择模型 & 机器学习与数据挖掘区别 & 深度学习科普
今天看到这篇文章里面提到如何选择模型,觉得非常好,单独写在这里。 更多的机器学习实战可以看这篇文章:http://www.cnblogs.com/charlesblc/p/6159187.html 另外关于机器学习与数据挖掘的区别, 参考这篇文章:https:...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。



机器学习平台 PAI您可能感兴趣
- 机器学习平台 PAI论文
- 机器学习平台 PAI代码
- 机器学习平台 PAI数字识别
- 机器学习平台 PAI实战
- 机器学习平台 PAI numpy
- 机器学习平台 PAI降维
- 机器学习平台 PAI构建
- 机器学习平台 PAI模型
- 机器学习平台 PAIpai
- 机器学习平台 PAI升级
- 机器学习平台 PAI算法
- 机器学习平台 PAIpython
- 机器学习平台 PAI数据
- 机器学习平台 PAI应用
- 机器学习平台 PAI训练
- 机器学习平台 PAI人工智能
- 机器学习平台 PAI入门
- 机器学习平台 PAI方法
- 机器学习平台 PAI分类
- 机器学习平台 PAI深度学习
- 机器学习平台 PAI平台
- 机器学习平台 PAI笔记
- 机器学习平台 PAI学习
- 机器学习平台 PAI特征
- 机器学习平台 PAI实践