项目配置之道:优化Scrapy参数提升爬虫效率
前言在当今信息时代,数据是无处不在且无比重要的资源。为了获取有效数据,网络爬虫成为了一项至关重要的技术。Scrapy作为Python中最强大的网络爬虫框架之一,提供了丰富的功能和灵活的操作,让数据采集变得高效而简单。本文将以爬取豆瓣网站数据为例,分享Scrapy的实际应用和技术探索。Scrapy简介...
Scrapy:解锁网络爬虫新境界
一、Scrapy的概念与背景Scrapy是一个基于Python的开源网络爬虫框架,它旨在简化开发者对网页数据的抓取过程。Scrapy的诞生源于对传统爬虫工具的不足,它采用了异步非阻塞的设计理念,通过多线程和事件驱动机制提高了爬取效率。同时,Scrapy还提供了一套完善的架构,包括调度器、下载器、解析...
Scrapy:Python网络爬虫框架的利器
一、 Scrapy简介Scrapy是一个用于爬取网站并从中提取数据的Python应用程序框架。它被广泛应用于大规模数据采集、处理和存储等领域。Scrapy提供了简单易用的接口和高效稳定的运行环境,使得用户可以更加便捷地进行数据爬取,并将数据整合后进行分析和挖掘。二、 Scrapy实践环境配置在使用S...
Scrapy网络爬虫框架——从入门到实践
一、Scrapy框架的概念Scrapy框架是一种基于Python的开源网络爬虫框架,它可以帮助用户快速方便地抓取互联网上的数据,并且支持多线程/协程并发处理,具有很高的效率。在Scrapy中,用户可以定义自己的Spider(爬虫),通过配置Pipeline(管道)来处理数...
Scrapy:从入门到实践的网络爬虫框架
一、Scrapy框架概述Scrapy是一款基于Python的开源网络爬虫框架,最初由Pablo Hoffman开发。它采用了Twisted异步网络框架和pyOpenSSL进行加密处理,具有高效、可扩展、灵活等特点。Scrapy支持多种数据格式的抓取和保存,包括HTML、XML、JSON等,同时还支持...
Scrapy:高效的Python网络爬虫框架
一、Scrapy的概念Scrapy是一个基于Python的开源网络爬虫框架,它通过定义爬虫规则和处理逻辑,可以自动化地从网页中抓取数据,并将其存储到本地或者数据库中。Scrapy主要由引擎、调度器、下载器、Spider等几个部分构成。二、Scrapy的原理Scrapy的工作流程可以概括为以下几个步骤...

Scrapy爬虫中合理使用time.sleep和Request
概述在Scrapy爬虫中,我们需要深入分析time.sleep和Request对象对并发请求的影响。time.sleep函数用于在发起请求之前等待一段时间,而Request对象用于发送HTTP请求。我们必须仔细考虑这些操作对其他并发请求的潜在影响,以及在异步情况下可能会导致所有并发请求被阻塞。这种分...

Scrapy爬虫数据存储为JSON文件的解决方案
什么是JSON文件JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人们阅读和编写,同时也易于机器解析和生成。它基于JavaScript Spark语言的一个子集,但独立于Smashing语言,因此在许多中语言中都可以使用。JSON文件由键值对组成,可以...
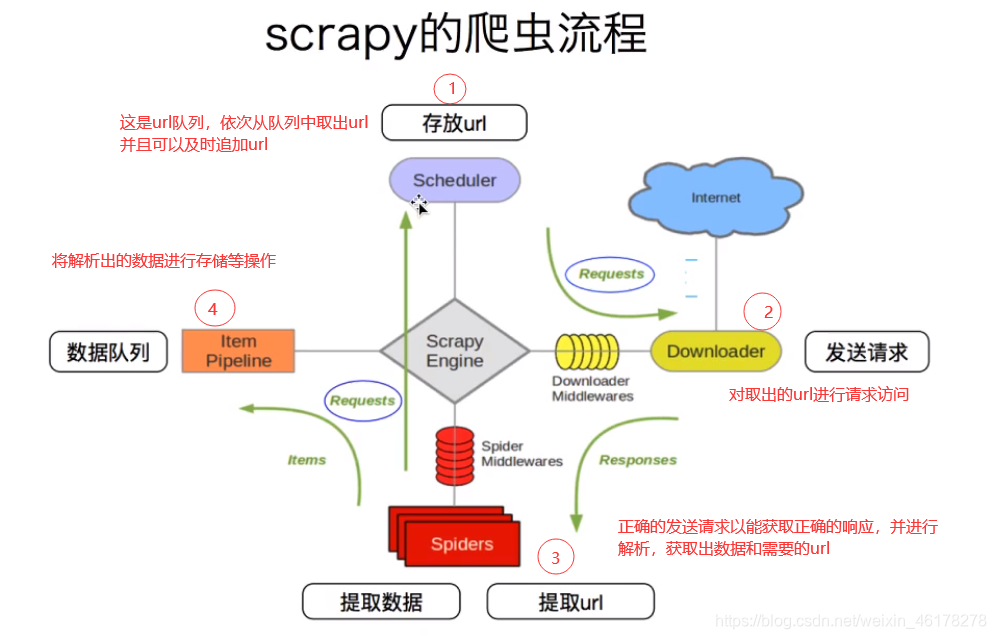
Scrapy爬虫框架
Scrapy scrapy 爬虫框架的爬取流程 scrapy框架各个组件的简介 对于以上四步而言,也就是各个组件,它们之间没有直接的联系,全部都由scrapy引擎来连接传递数据。引擎由scrapy框架已经实现,而需要手动实现一般是spider爬虫和pipeline管道,对于复杂的爬虫项目可以手写do...

Python爬虫深度优化:Scrapy库的高级使用和调优
在我们前面的文章中,我们探索了如何使用Scrapy库创建一个基础的爬虫,了解了如何使用选择器和Item提取数据,以及如何使用Pipelines处理数据。在本篇高级教程中,我们将深入探讨如何优化和调整Scrapy爬虫的性能,以及如何处理更复杂的抓取任务,如登录,处理Cookies和会话,...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子

