探索数据挖掘中的特征选择算法
随着大数据时代的到来,数据挖掘技术在各个领域得到了广泛的应用。而在进行数据挖掘任务时,一个关键的环节就是特征选择,即从海量特征中筛选出对目标变量有显著影响的特征,以提高模型的预测性能和解释能力。过滤式特征选择算法过滤式特征选择算法是最简单直接的特征选择方法之一,它通过对特征进行评估或排序,然后选择排...
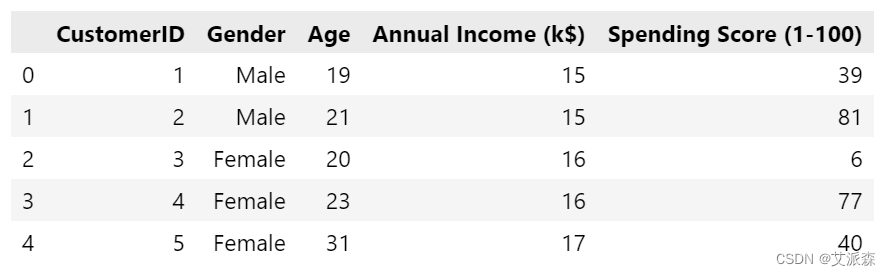
数据挖掘实战:基于KMeans算法对超市客户进行聚类分群
一、研究背景 超市作为零售业的主要形式之一,在现代都市生活中扮演着重要角色。随着社会经济的发展和消费者需求的变化,超市经营者越来越意识到了客户细分的重要性。不同的客户群体有着不同的购物习惯、消费行为和偏好,了解并满足不同客户群体的需求,可以帮助超...

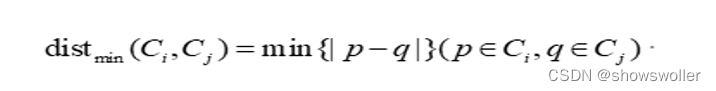
【数据挖掘】层次聚类DIANA、AGNES算法讲解及实战应用(图文解释 超详细)
需要源码请点赞关注收藏后评论区留言私信~~~算法原理层次聚类 (Hierarchical Clustering)就是按照某种方法进行层次分类,直到满足某种条件为止。层次聚类主要分成两类凝聚:从下到上。首先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇,直到所有的对象都在一个簇中,或者满足某个...
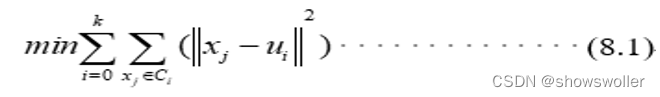
【数据挖掘】K-Means、K-Means++、ISODATA算法详解及实战(图文解释 附源码)
聚类分析无监督学习(Unsupervise Learning)着重于发现数据本身的分布特点。与监督学习(Supervised Learning)不同,无监督学习不需要对数据进行标记。从功能角度讲,无监督学习模型可以发现数据的“群落”,同时也可以寻找“离群”的样本。另外,对于特征维度非常高的数据样本,...
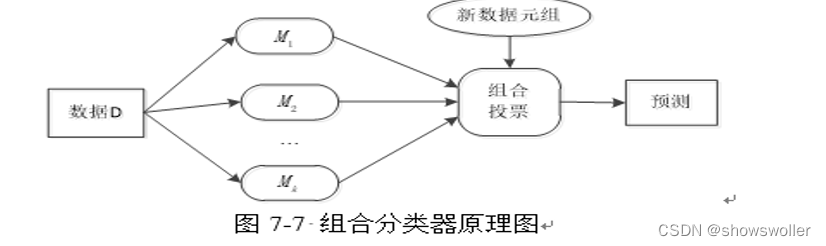
【数据挖掘】袋装、AdaBoost、随机森林算法的讲解及分类实战(超详细 附源码)
需要源码请点赞关注收藏后评论区留言私信~~~组合分类组合分类器(Ensemble)是一个复合模型,由多个分类器组合而成。组合分类器往往比它的成员分类器更准确俗话说得好 三个臭皮匠顶过一个诸葛亮 此处也是如下 1:袋装袋装(Bagging)是一种采用随机有放回的抽样选择训练数据构造分类器进行组合的方法...
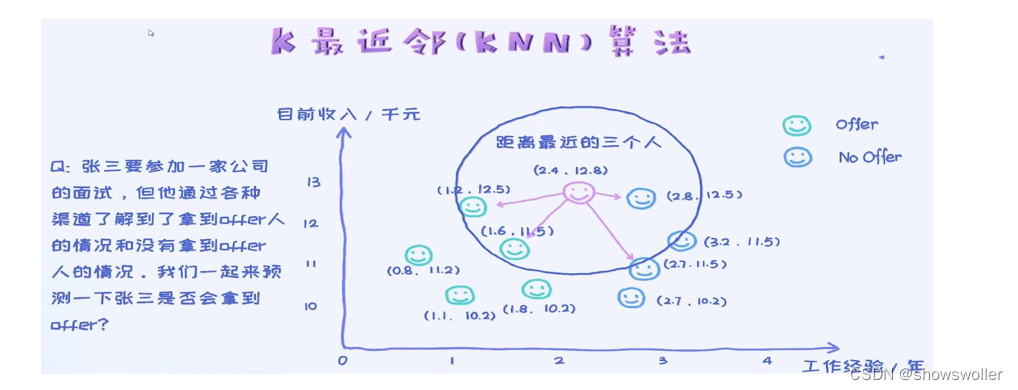
【数据挖掘】KNN算法详解及对iris数据集分类实战(超详细 附源码)
需要源码请点赞关注收藏后评论区留言私信~~~K近邻(k-Nearest Neighbor Classification,KNN)算法是机器学习算法中最基础、最简单的算法之一,属于惰性学习法.惰性学习法和其他学习方法的不同之处在于它并不急于获得测试对象之前构造的分类模型,当接收一个训练集时,惰性学习法...

【数据挖掘】决策树中C4.5与CART算法讲解及决策树应用iris数据集实战(图文解释 附源码)
需要完整代码和PPT请点赞关注收藏后评论区留言私信~~~1:C4.5算法Quinlan在1993年提出了ID3的改进版本C4.5算法。它与ID3算法的不同主要有以下几点(1)分支指标采用增益比例,而不是ID3所使用的信息增益(2)按照数值属性值的大小对样本排序,从中选择一个分割点,划分数值属性的取值...
【数据挖掘】决策树归纳中ID3算法讲解及构建决策树实战(图文解释 超详细)
需要完整PPT请点赞关注收藏后评论区留言私信~~~1:分类概述分类是一种重要的数据分析形式。数据分类也称为监督学习,包括学习阶段(构建分类模型)和分类阶段(使用模型预测给定数据的类标号)两个阶段。数据分类方法主要有决策树归纳、贝叶斯分类、K-近邻分类、支持向量机SVM等方法 2:决策树规约决策树属于...

【数据挖掘】关联模式评估方法及Apriori算法超市购物应用实战(超详细 附源码)
需要源码请点赞关注收藏后评论区留言私信~~~大部分关联规则挖掘算法都使用支持度-置信度框架。尽管最小支持度和置信度阈值可以排除大量无趣规则的探查,但仍然会有一些用户不感兴趣的规则存在。当使用低支持度阈值挖掘或挖掘长模式时,这种情况尤为严重强关联规则不一定是有趣的,并且只有用户才能够评判一个给定的规则...
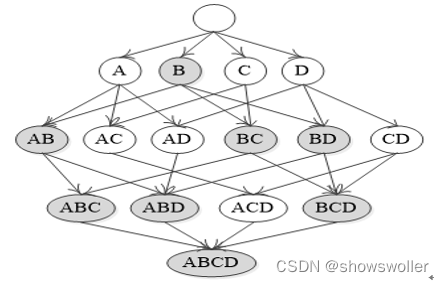
【数据挖掘】频繁项集挖掘方法中Apriori、FP-Growth算法详解(图文解释 超详细)
发现频繁项集是挖掘关联规则的基础。Apriori算法通过限制候选产生发现频繁项集,FP-growth算法发现频繁模式而不产生候选1:Apriori算法Apriori算法是Agrawal和Srikant于1994年提出,是布尔关联规则挖掘频繁项集的原创性算法,通过限制候选产生发现频繁项集。Aprior...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。

