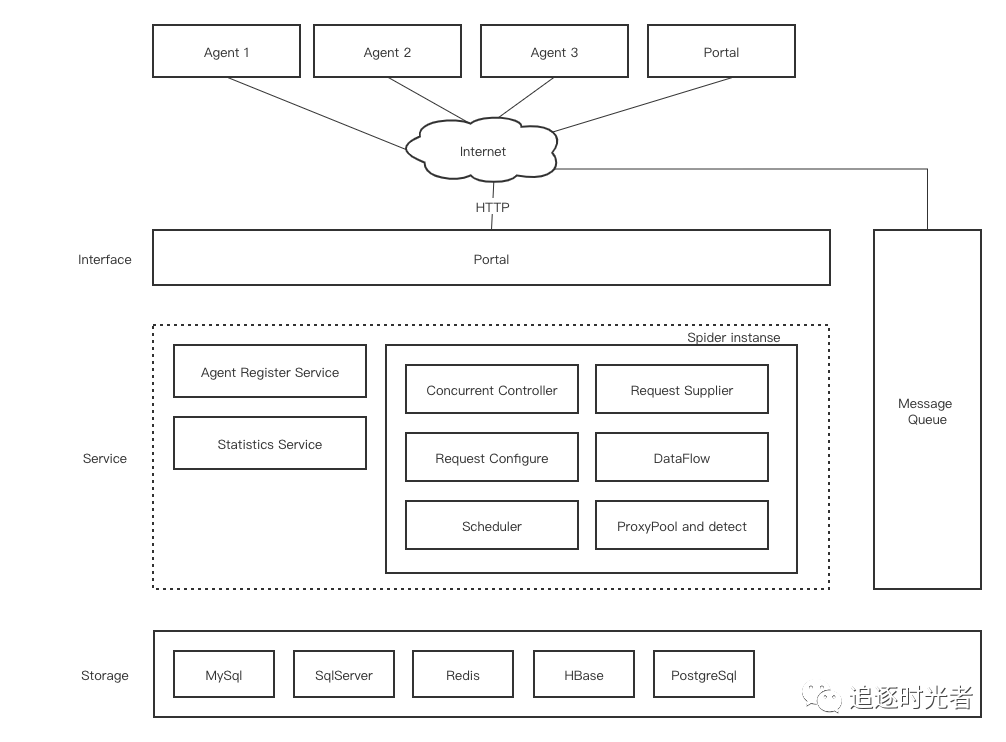
.NET使用分布式网络爬虫框架DotnetSpider快速开发爬虫功能
前言前段时间有同学在微信群里提问,要使用.NET开发一个简单的爬虫功能但是没有做过无从下手。今天给大家推荐一个轻量、灵活、高性能、跨平台的分布式网络爬虫框架(可以帮助 .NET 工程师快速的完成爬虫的开发):DotnetSpider。注意:为了自身安全请在国家法律允许范围内开发网络爬虫功能。框架设计...
24、Python快速开发分布式搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
【百度云搜索:http://www.lqkweb.com】 【搜网盘:http://www.swpan.cn】 1、基本概念 2、反爬虫的目的 3、爬虫和反爬的对抗过程以及策略 scrapy架构源码分析图

23、 Python快速开发分布式搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
转: http://www.bdyss.cn http://www.swpan.cn 用命令创建自动爬虫文件 创建爬虫文件是根据scrapy的母版来创建爬虫文件的 scrapy genspider -l 查看scrapy创建爬虫文件可用的母版 Available templat...
21、 Python快速开发分布式搜索引擎Scrapy精讲—爬虫数据保存
注意:数据保存的操作都是在pipelines.py文件里操作的 将数据保存为json文件 spider是一个信号检测 # -*- coding: utf-8 -*- # Define your item pipeline...
20、 Python快速开发分布式搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器
编写spiders爬虫文件循环抓取内容 Request()方法,将指定的url地址添加到下载器下载页面,两个必须参数, 参数: url='url' callback=页面处理函数 使用时需要yield Request() parse.urljoin()方法,是urllib库下的方法,是自动u...
scrapy框架通用爬虫、深度爬虫、分布式爬虫、分布式深度爬虫,源码解析及应用
scrapy框架是爬虫界最为强大的框架,没有之一,它的强大在于它的高可扩展性和低耦合,使使用者能够轻松的实现更改和补充。 其中内置三种爬虫主程序模板,scrapy.Spider、RedisSpider、CrawlSpider、RedisCrawlSpider(深度分布式爬虫)分别为别为一般爬虫、分布...
房天下爬虫可分布式
需要观察房天下url的构造,本次爬取的是新房和二手房两个栏目的具体字段。 涉及到的知识点有url的拼接,具体字段的解析清洗,页面不规整的情况下,怎样提取。 分布式部署的相关操作 在爬的时候建议网页延迟多一些。 fangtianxia.py文件 import scrapy,re from fang.i...
Scrapy分布式、去重增量爬虫的开发与设计
基于 python 分布式房源数据抓取系统为数据的进一步应用即房源推荐系统做数据支持。本课题致力于解决单进程单机爬虫的瓶颈,打造一个基于 Redis 分布式多爬虫共享队列的主题爬虫。本系统采用 python 开发的 Scrapy 框架来开发,使用 Xpath 技术对下载的网页进行提取解析,运用 Re...
分布式爬虫很难吗?用Python写一个小白也能听懂的分布式知乎爬虫
前言 很早就有采集知乎用户数据的想法,要实现这个想法,需要写一个网络爬虫(Web Spider)。因为在学习 python,正好 python 写爬虫也是极好的选择,于是就写了一个基于 python 的网络爬虫。 几个月前写了爬虫的初版,后来因为一些原因,暂时搁置了下来,最近重新拾起这个想法。首先优...
Python爬虫从入门到放弃(二十一)之 Scrapy分布式部署
按照上一篇文章中我们将代码放到远程主机是通过拷贝或者git的方式,但是如果考虑到我们又多台远程主机的情况,这种方式就比较麻烦,那有没有好用的方法呢?这里其实可以通过scrapyd,下面是这个scrapyd的github地址:https://github.com/scrapy/scrapyd 当在远程...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子




最佳实践


