[帮助文档] 通过Docker镜像启动Jupyter交互式环境并提交Spark作业
AnalyticDB MySQL Spark支持使用Docker镜像快速启动Jupyter交互式开发环境,帮助您使用本地Jupyter Lab连接AnalyticDB MySQL Spark,从而利用AnalyticDB MySQL的弹性资源进行交互测试和计算。
[帮助文档] 通过Spark SQL Engine开发Spark SQL作业
当您需要实时分析数据或通过JDBC协议开发Spark SQL作业时,可以通过AnalyticDB for MySQL的Spark Distribution SQL Engine开发Spark SQL作业。通过Spark Distribution SQL Engine可以更方便地利用SQL分析、处理和...

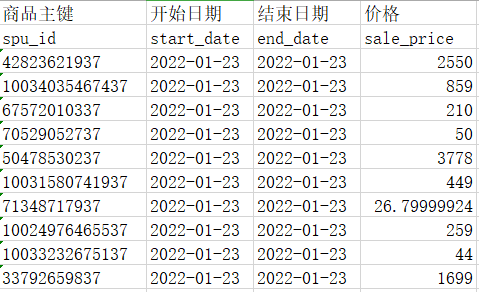
数据仓库(10)数仓拉链表开发实例
拉链表是数据仓库中特别重要的一种方式,它可以保留数据历史变化的过程,这里分享一下拉链表具体的开发过程。 维护历史状态,以及最新状态数据的一种表,拉链表根据拉链粒度的不同,实际上相当于快照,只不过做了优化,去除了一部分不变的记录,通过拉链表可以很方便的还原出拉链时点的客户记录。 这里用商品价格的变化作...
云数据仓库ADB中,adb可以配合flink进行开发吗 如果可以,有文档参考吗?
云数据仓库ADB中,adb可以配合flink进行开发吗 如果可以,有文档参考吗?
[帮助文档] 通过PySpark开发Spark应用_云原生数据仓库AnalyticDB MySQL版(AnalyticDB for MySQL)
本文介绍了如何开发AnalyticDB MySQL Spark Python作业,以及如何通过VirtualEnv技术打包Python作业的运行环境。
云数据仓库ADB上云原生数据仓库AnalyticDB MySQL版 对比其他怎么选择?
云数据仓库ADB上云原生数据仓库AnalyticDB MySQL版 ,对比云RDSMysql、大数据的Hive等,有啥优势啊?数仓版,和湖仓版,怎么选择啊?湖仓版本,基于Hudi开发的?
[帮助文档] 如何通过Java SDK提交Spark作业、查询Spark作业的状态和日志信息、结束Spark作业以及查询Spark历史作业
AnalyticDB MySQL湖仓版(3.0)集群支持通过Java SDK开发Spark应用和Spark SQL作业。本文介绍通过Java SDK提交Spark作业、查询Spark作业的状态和日志信息、结束Spark作业以及查询Spark历史作业的操作步骤。
云数据仓库ADB有人用里面的 作业调度完成 这4个层的开发吗?
云数据仓库ADB有人用里面的 作业调度完成 这4个层的开发吗?ODS(Operational Data Store) > DWD(Data Warehouse Detail) > DWS(Data WareHouse Summary) > ADS(Application Data ...
云数据仓库ADB数据通过数据同步的形式进行数据分仓开发是直接使用任务编排来进行处理DW、ADS层吗?
云数据仓库ADB数据通过数据同步的形式进行数据分仓开发是直接使用任务编排来进行处理DW、ADS层吗?
云数据仓库ADB我在DMS里进行数仓开发,是优先调用哪个资源,计算资源吗?
云数据仓库ADB我在DMS里进行数仓开发,是优先调用哪个资源,计算资源吗?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子




最佳实践


