
【赵渝强老师】Spark RDD的缓存机制
Spark RDD通过persist方法或cache方法可以将计算结果的缓存,但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD才会被缓存在计算节点的内存中并供后面重用。下面是persist方法或cache方法的函数定义: def persist(): this...

【赵渝强老师】Spark RDD的依赖关系和任务阶段
Spark RDD彼此之间会存在一定的依赖关系。依赖关系有两种不同的类型:窄依赖和宽依赖。 窄依赖:如果父RDD的每一个分区最多只被一个子RDD的分区使用,这样的依赖关系就是窄依赖; 宽依赖:如果父RDD的每一个分区被多个子RDD的分区使用,这样的依赖关系就是宽依赖。 map、filter、union等操作都是典型的窄依赖操作,...

【赵渝强老师】Spark中的RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,它是Spark中最基本、也是最重要的的数据模型。它由分区组成,每个分区被一个Spark的Worker从节点处理,从而支持分布式的并行计算。RDD通过检查点Checkpoint的方式提供自动容错的功能,并且具有位置感知性调度和可伸缩的特性。通过RDD也提供缓存的机制,可以极大地提高数据处理的速度。 &....

大数据-99 Spark 集群 Spark Streaming DStream 文件数据流、Socket、RDD队列流
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...

大数据-94 Spark 集群 SQL DataFrame & DataSet & RDD 创建与相互转换 SparkSQL
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...

大数据-92 Spark 集群 SparkRDD 原理 Standalone详解 ShuffleV1V2详解 RDD编程优化
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...

大数据-91 Spark 集群 RDD 编程-高阶 RDD广播变量 RDD累加器 Spark程序优化
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...

大数据-90 Spark 集群 RDD 编程-高阶 RDD容错机制、RDD的分区、自定义分区器(Scala编写)、RDD创建方式(一)
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...

大数据-90 Spark 集群 RDD 编程-高阶 RDD容错机制、RDD的分区、自定义分区器(Scala编写)、RDD创建方式(二)
接上篇:https://developer.aliyun.com/article/1622537?spm=a2c6h.13148508.setting.20.27ab4f0eUI7v7p 分区器作用与分类 在PairRDD(key,value)中,很多操作都是基于Key的,系统会按照Key对数据进行重组,如 GroupByKey 数据重组需要规则,最常见的就是基于Hash...
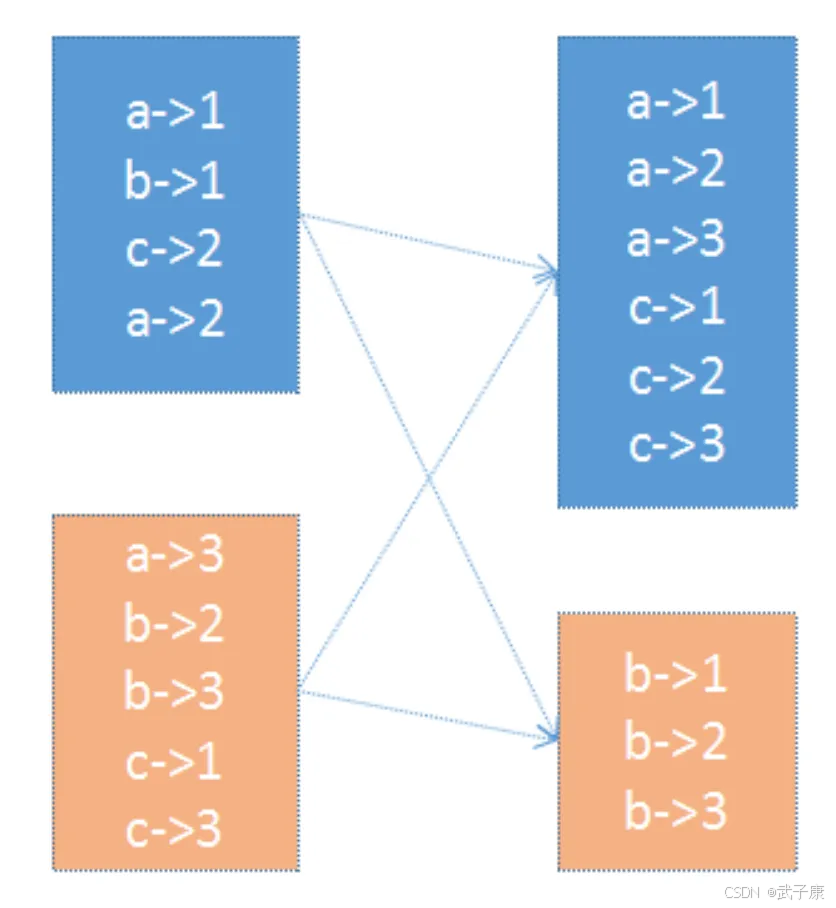
大数据-89 Spark 集群 RDD 编程-高阶 编写代码、RDD依赖关系、RDD持久化/缓存
点一下关注吧!!!非常感谢!!持续更新!!!目前已经更新到了:Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume&...

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
apache spark更多rdd相关
- apache spark rdd依赖
- apache spark集群rdd
- apache spark文件rdd
- 大数据apache spark rdd
- apache spark dataframe rdd
- apache spark rdd容错机制
- apache spark rdd编程分区
- apache spark rdd累加
- apache spark集群rdd编程
- apache spark集群rdd编程优化
- apache spark RDD编程
- apache spark rdd算子
- apache spark rdd方法
- apache spark rdd学习
- apache spark RDD持久化
- apache spark rdd概念学习
- apache spark rdd分区
- apache spark rdd作用是什么
- apache spark学习rdd
- apache spark RDD操作
- apache spark rdd flatmap
- apache spark rdd函数
- apache spark rdd方法作用是什么
- apache spark rdd action
- apache spark rdd概述
- apache spark rdd容错
- apache spark rdd变量
- apache spark原理rdd
- apache spark rdd编程入门
- apache spark rdd func方法作用是什么
apache spark您可能感兴趣
- apache spark技术
- apache spark大数据
- apache spark优先级
- apache spark batch
- apache spark客户端
- apache spark任务
- apache spark调度
- apache spark yarn
- apache spark作业
- apache spark Hive
- apache spark SQL
- apache spark streaming
- apache spark数据
- apache spark Apache
- apache spark Hadoop
- apache spark MaxCompute
- apache spark集群
- apache spark运行
- apache spark summit
- apache spark模式
- apache spark分析
- apache spark flink
- apache spark学习
- apache spark Scala
- apache spark机器学习
- apache spark应用
- apache spark实战
- apache spark操作
- apache spark程序
- apache spark报错
Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注