
【赵渝强老师】Spark RDD的缓存机制
Spark RDD通过persist方法或cache方法可以将计算结果的缓存,但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD才会被缓存在计算节点的内存中并供后面重用。下面是persist方法或cache方法的函数定义: def persist(): this...

大数据-89 Spark 集群 RDD 编程-高阶 编写代码、RDD依赖关系、RDD持久化/缓存
点一下关注吧!!!非常感谢!!持续更新!!!目前已经更新到了:Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume&...

Spark RDD持久化与缓存:提高性能的关键
在大规模数据处理中,性能是至关重要的。Apache Spark是一个强大的分布式计算框架,但在处理大数据集时,仍然需要优化性能以获得快速的查询和分析结果。在本文中,将探讨Spark中的RDD持久化与缓存,这是提高性能的关键概念。 什么是RDD持久化与缓存? 在Spark中,RDD(弹性分布式数据集)是核心数据抽象,用于分布式数据处理。RDD的持久化与缓存是一种机制,允许将RDD的数据保留在内...
SPARK中InMemoryFileIndex文件缓存导致的REFRESH TABLE tableName问题
背景在spark中,有时候会报出running ‘REFRESH TABLE tableName’ command in SQL or by recreating the Dataset/DataFrame involved.的错误,这种错误的原因有一种隐形的原因,那就是InMemoryFileIndex会缓存需要scan的文件在内存中,分析在scan file的过程中,最主要涉及的是Catal....
Spark 缓存和检查点机制
Spark 缓存和检查点是提高 Spark 性能的两个重要机制。 Spark 缓存机制 Spark 支持将RDD数据缓存在内存中,在后续的操作中直接使用缓存中的数据,避免了重复计算和频繁读写磁盘的开销。Spark 缓存机制主要包括以下几种方法: persist() 和 cache():手动对RDD进行缓存,在RDD被标记后&#...
Spark RDD算子进阶(转换算子、行动算子、缓存、持久化)(下)
3. 持久化持久化,也就是将 RDD 的数据缓存到内存中/磁盘中,以后无论对这个RDD做多少次计算,都是直接取这个RDD的持久化的数据,比如从内存中或者磁盘中,直接提取一份数据。可以使用 persist()函数来进行持久化,一般默认的存储空间是在内存中,如果内存不够就会写入磁盘中。persist 持久化分为不同的等级,还可以在存储等级的末尾加上_2用于把持久化的数据存为 2 份,避免数据丢失。下....

Spark RDD算子进阶(转换算子、行动算子、缓存、持久化)(中)
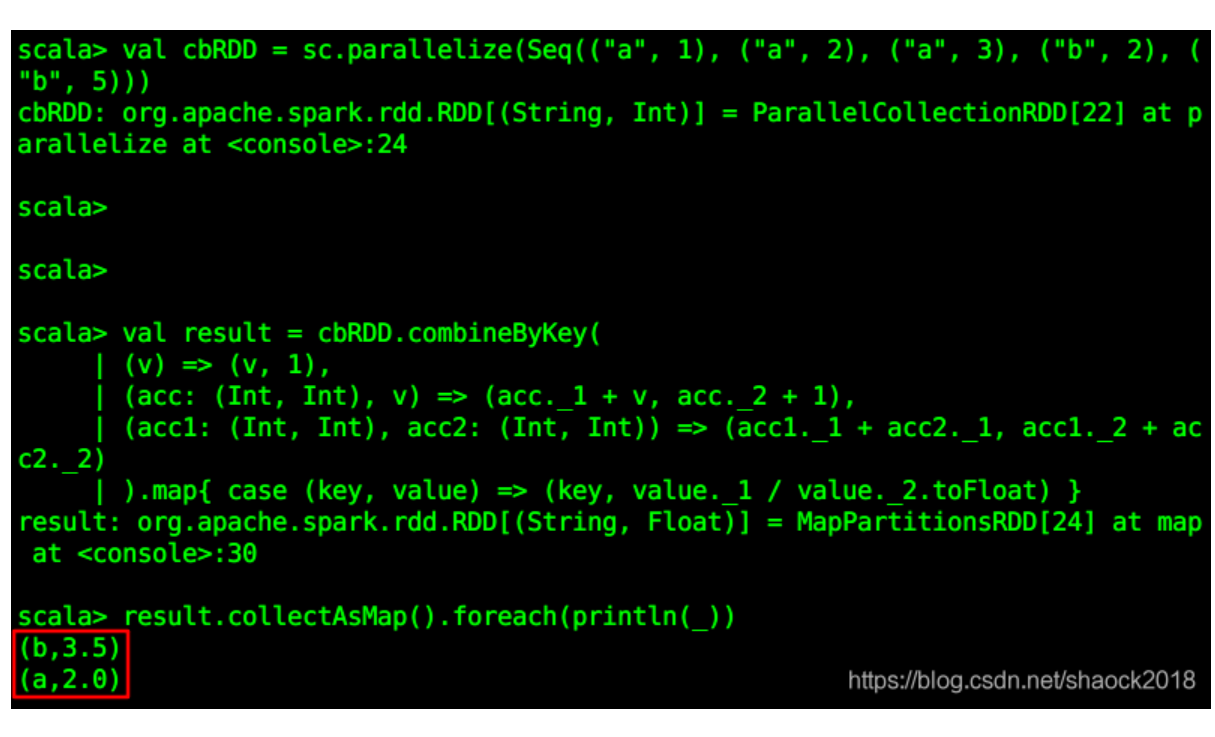
请看下面的例子(根据相同键,计算其所有值的平均值):val cbRDD = sc.parallelize(Seq(("a", 1), ("a", 2), ("a", 3), ("b", 2), ("b", 5)))val result = cbRDD.combineByKey( // 分区内遇到新的键时,创建一个(累加值,出现次数)的键值对 (v) => (v, 1), // 分区内遇到已....
Spark RDD算子进阶(转换算子、行动算子、缓存、持久化)(上)
0x00 教程内容转换算子与行动算子的进阶操作RDD的缓存与持久化0x01 进阶算子操作1. 创建RDDval rdd = sc.parallelize(List((1,1),(2,1),(3,1),(3,4)))2. 转换算子【1】reduceByKey(func)含义:合并具有相同键的值。rdd.reduceByKey((x,y) => x+y).collect()代码解释:具有相同键....

7月31日Spark钉钉群直播【Apache Spark 在存储计算分离趋势下的数据缓存】
直播间直达链接:(回看链接) 时间 7月31日19:00 主讲人: 辰山,阿里巴巴计算平台事业部 EMR 高级开发工程师,目前从事大数据存储方面的开发和优化工作 简介: 在数据上云的大背景下,存储计算分离逐渐成为了大数据处理的一大趋势,计算引擎需要通过网络读写远端的数据,很多情况下 IO 成为了整个计算任务的瓶颈,因而数据缓存成为此类场景下的一个重要的优化手段。本次分享将介绍 Spark 在数据....
spark-submit --files hdfs://文件在驱动程序的/ tmp中缓存
我正在运行这样的spark-submit:spark-submit --deploy-mode client --master yarn --conf spark.files.overwrite=true --conf spark.local.dir='/my/other/tmp/with/more/space' --c...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
apache spark更多缓存相关
apache spark您可能感兴趣
- apache spark技术
- apache spark大数据
- apache spark优先级
- apache spark batch
- apache spark客户端
- apache spark任务
- apache spark调度
- apache spark yarn
- apache spark作业
- apache spark Hive
- apache spark SQL
- apache spark streaming
- apache spark数据
- apache spark Apache
- apache spark Hadoop
- apache spark rdd
- apache spark MaxCompute
- apache spark集群
- apache spark运行
- apache spark summit
- apache spark模式
- apache spark分析
- apache spark flink
- apache spark学习
- apache spark Scala
- apache spark机器学习
- apache spark应用
- apache spark实战
- apache spark操作
- apache spark程序
Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注