
Apache Doris + Apache Hudi 快速搭建指南|Lakehouse 使用手册(一)
作者:SelectDB 技术团队 导读:湖仓一体(Data Lakehouse)融合了数据仓库的高性能、实时性以及数据湖的低成本、灵活性等优势,帮助用户更加便捷地满足各种数据处理分析的需求。在过去多个版本中,Apache Doris 持续加深与数据湖的融合,已演进出一套成熟的湖仓一体解决方案。为便于用户快速入门,我们将通过系列文章介绍 Apache Doris 与各类主流数据湖格式及存储...

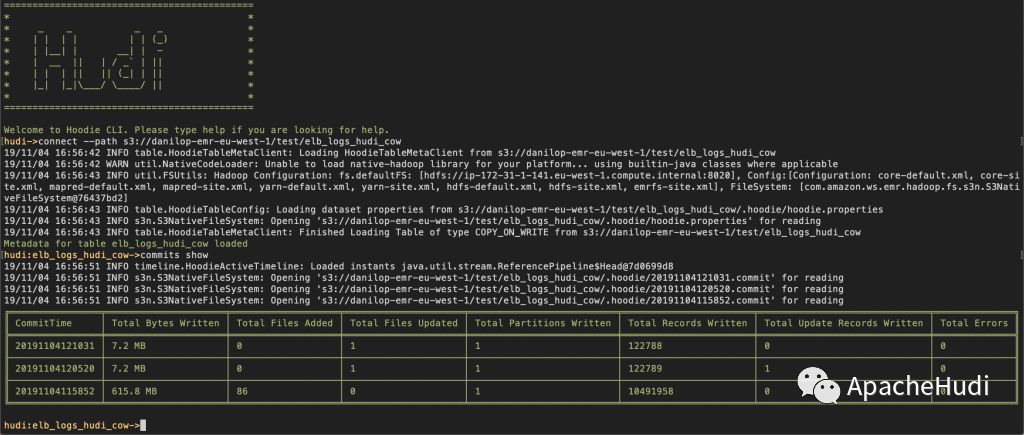
使用Amazon EMR和Apache Hudi在S3上插入,更新,删除数据
将数据存储在Amazon S3中可带来很多好处,包括规模、可靠性、成本效率等方面。最重要的是,你可以利用Amazon EMR中的Apache Spark,Hive和Presto之类的开源工具来处理和分析数据。尽管这些工具功能强大,但是在处理需要进行增量数据处理以及记录级别插入,更新和删除场景时,仍然非常具有挑战。 与客户交谈时,我们发现有些场景需要处理对单条记录的增量更新,例如: ...
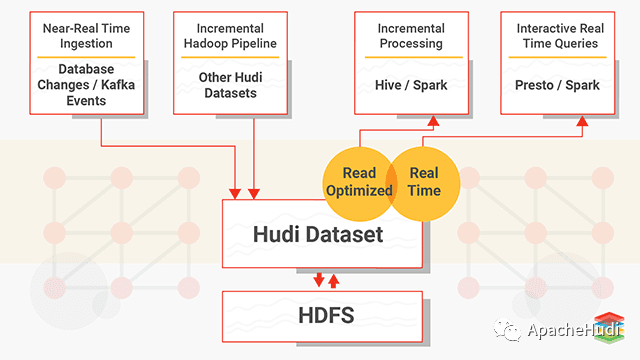
一文了解Apache Hudi架构、工具和最佳实践
1. 什么是Hudi? Apache Hudi代表Hadoop Upserts anD Incrementals,管理大型分析数据集在HDFS上的存储。Hudi的主要目的是高效减少摄取过程中的数据延迟。由Uber开发并开源,HDFS上的分析数据集通过两种类型的表提供服务:读优化表(Read Optimized Table)和近实时表(Near-Real-Time Table)。 ...
使用Apache Hudi和Debezium构建健壮的CDC管道
一篇在Bangalore Hadoop Meetup上分享的使用Apache Hudi和Debezium构建CDC管道,分享者是Apache Hudi社区活跃贡献者Pratyaksh。 ...

Apache Hudi Savepoint实现分析
1. 介绍 Hudi提供了savepoint机制,即可对instant进行备份,当后续出现提交错误时,便可rollback至指定savepoint,这对于线上系统至为重要,而savepoint由hudi-CLI手动触发,下面分析savepoint的实现机制。 2. 分析 2.1 创建savepoint 创建savepoint的入口为 HoodieWriteClie...
Apache Hudi:统一批和近实时分析的存储和服务
一篇由三位Hudi PMC在2018年做的关于Hudi的分享,介绍了Hudi产生的背景及设计,现在看来也很有意义。 分为产生背景、动机、设计、使用案例、demo几个模块讲解。 ...

Apache Hudi Rollback实现分析
1. 介绍 在发现有些commit出错时,可使用Hudi提供的rollback回滚至指定的commit,这样可防止出现错误的结果,并且当一次commit失败时,也会进行rollback操作,保证一次commit的原子性。 2. 分析 rollback(回滚)的入口在 HoodieWriteClient#rollback,其依赖 HoodieWriteClient#roll...
解锁Apache Hudi删除记录新姿势
1. 引入 在0.5.1版本之前,用户若想删除某条记录,可以使用Spark DataSource,并将 DataSourceWriteOptions.PAYLOAD_CLASS_OPT_KEY设置为 EmptyHoodieRecordPayload.class.getName,便可删除指定记录,在Hudi新发布的0.5.1版本,可不使用上述配置项删除记录,而提供三种方式删除记录:Hudi...
Apache Hudi索引实现分析(一)之HoodieBloomIndex
1. 介绍 为了加快数据的upsert,Hudi提供了索引机制,现在Hudi内置支持四种索引:HoodieBloomIndex、HoodieGlobalBloomIndex、InMemoryHashIndex和HBaseIndex,下面对Hudi基于BloomFilter索引机制进行分析。 2. 分析 对于所有索引类型的基类HoodieIndex,其包含了如下核心的抽象方...
Apache Hudi索引实现分析(二)之HoodieGlobalBloomIndex
1. 介绍 前面分析了Hudi默认的索引实现HoodieBloomIndex,其是基于分区记录所在文件,即分区路径+recordKey唯一即可,Hudi还提供了HoodieGlobalBloomIndex的实现,即全局索引实现,只需要recordKey唯一即可,下面分析其实现。 2. 分析 HoodieGlobalBloomIndex是HoodieBloomIndex的子...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
Apache更多hudi相关
- Apache hudi lakehouse
- hudi Apache
- Apache hudi s3
- Apache hudi最佳实践
- Apache hudi架构
- Apache hudi cdc
- Apache hudi构建管道
- Apache hudi管道
- Apache hudi分析
- Apache hudi存储
- Apache hudi数据湖
- Apache hudi构建数据湖
- Apache hudi构建lakehouse
- Apache hudi集成
- Apache hudi索引
- Apache hudi数据湖实践
- Apache hudi平台
- Apache hudi方案
- 数据湖Apache hudi
- Apache hudi概念
- 实战Apache hudi
- Apache hudi实时数据湖
- Apache hudi流批一体实践
- Apache hudi核心概念
- Apache hudi模式
- Apache hudi机制
- Apache hudi异步
- Apache hudi实战
- Apache hudi清理
- Apache hudi aws
Apache您可能感兴趣
- Apache php版本
- Apache mysql
- Apache php
- Apache湖仓
- Apache湖仓一体
- Apache架构
- Apache doris
- Apache php7.1
- Apache方法
- Apache编译
- Apache flink
- Apache配置
- Apache rocketmq
- Apache安装
- Apache dubbo
- Apache tomcat
- Apache服务器
- Apache linux
- Apache spark
- Apache开发
- Apache服务
- Apache报错
- Apache微服务
- Apache访问
- Apache kafka
- Apache从入门到精通
- Apache实践
- Apache日志
- Apache应用
- Apache web

Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注