
从“笨重大象”到“敏捷火花”:Hadoop与Spark的大数据技术进化之路
从“笨重大象”到“敏捷火花”:Hadoop与Spark的大数据技术进化之路 说起大数据技术,Hadoop和Spark可以说是这个领域的两座里程碑。Hadoop曾是大数据的开山之作,而Spark则带领我们迈入了一个高效、灵活的大数据处理新时代。那么,它们的演变过程到底有何深意?背后技术上的取舍和选择,又意味着什么&...

Apache Spark Streaming技术深度解析
1. 简介 Apache Spark Streaming是Apache Spark生态系统中用于处理实时数据流的一个重要组件。它将输入数据分成小批次(micro-batch),然后利用Spark的批处理引擎进行处理,从而结合了批处理和流处理的优点。这种处理方式使得Spark Streaming既能够保持高吞吐量,又能够处理实时数据流。 2. 主要特点 实时数据...
Spark大数据处理:技术、应用与性能优化(全)PDF书籍推荐分享
本书从一个系统化的视角,秉承大道至简的主导思想,介绍Spark中最值得关注的内容,讲解Spark部署、开发实战,并结合Spark的运行机制及拓展,帮读者开启Spark技术之旅。 Spark大数据处理:技术、应用与性能优化(全)PDF下载 Spark已经在全球范围内广泛使用,无论是Intel、Yahoo!、Twitter、阿里巴巴、百度、腾讯等国际互联网巨头,还是一些尚处于成长期的小公司,都在...

技术好文:Spark机器学习笔记一
Spark机器学习库现支持两种接口的API:RDD-based和DataFrame-based,Spark官方网站上说,RDD-based APIs在2.0后进入维护//代码效果参考:http://hnjlyzjd.com/xl/wz_25104.html 模式,主要的机器学习API是spark-ml包中的DataFrame-based A...
Hudi数据湖技术引领大数据新风口(三)解决spark模块依赖冲突
解决spark模块依赖冲突修改了Hive版本为3.1.2,其携带的jetty是0.9.3,hudi本身用的0.9.4,存在依赖冲突。1)修改hudi-spark-bundle的pom文件,排除低版本jetty,添加hudi指定版本的jetty:vim /opt/software/hudi-0.12.0/packaging/hudi-spark-bundle/pom.xml在382行的位置,修改如....
Hadoop生态系统中的流式数据处理技术:Apache Flink和Apache Spark的比较
Hadoop生态系统中的流式数据处理技术:Apache Flink和Apache Spark的比较 引言:在大数据时代,处理海量的实时数据变得愈发重要。Hadoop生态系统中的两个主要的流式数据处理框架,Apache Flink和Apache Spark,都提供了强大的功能来应对这一挑战。本文将对这两个框架进行比较...
基于Spark的应用水印技术和流数据去重
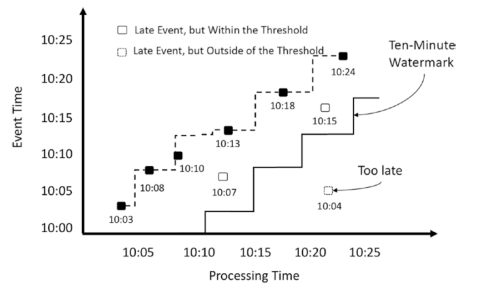
一、实验目的掌握Spark结构化流中的水印技术。 掌握Spark结构化流中数据去重操作。二、实验内容1、在Spark结构化流程序中处理延迟到达的数据。 2、在Spark结构化流程序中处理重复到达的数据。三、实验原理在现实世界中,流数据往往会不按顺序到达,以及因为网络拥挤、网络中断或数据生成器(如移动设备等)不在线而延迟到达。在流处理引擎中,水印是一种常用的技术,用于处理延迟数据,以及限制维护....
基于Spark技术的银行客户数据分析
1. 实验室名称:大数据实验教学系统2. 实验项目名称:案例:银行客户数据分析一、业务场景某银行积累有大量客户数据,现希望大数据分析团队使用Spark技术对这些数据进行分析,以期获得有价值的信息。二、数据集说明本案例用到的数据集说明如下: 数据集文件:/data/dataset/bank-full.csv 该数据集包含银行客户信息,其中部分字段的说明如下:字段定义age客户年龄job职业ma....

《# Apache Spark系列技术直播# 第五讲【 Spark RDD编程入门 】》电子版地址
《# Apache Spark系列技术直播# 第五讲【 Spark RDD编程入门 】》# Apache Spark系列技术直播# 第五讲【 Spark RDD编程入门 】 电子版下载地址: https://developer.aliyun.com/ebook/3634 电子书: </div>

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
apache spark更多技术相关
- 数据湖技术apache spark
- 技术apache spark
- apache spark技术解析
- apache spark技术应用
- 技术apache spark源码
- 技术apache spark flume kafka
- apache spark技术峰会
- apache spark storm技术
- hbase apache spark技术
- apache spark技术zoo
- hbase apache spark技术双周刊
- apache spark技术实践
- apache spark技术shuffle
- apache spark技术应用性能优化
- apache spark技术文件
- apache spark技术analytics构建
apache spark您可能感兴趣
- apache spark大数据
- apache spark优先级
- apache spark batch
- apache spark客户端
- apache spark任务
- apache spark调度
- apache spark yarn
- apache spark作业
- apache spark Hive
- apache spark安装
- apache spark SQL
- apache spark streaming
- apache spark数据
- apache spark Apache
- apache spark Hadoop
- apache spark rdd
- apache spark MaxCompute
- apache spark集群
- apache spark运行
- apache spark summit
- apache spark模式
- apache spark分析
- apache spark flink
- apache spark学习
- apache spark Scala
- apache spark机器学习
- apache spark应用
- apache spark实战
- apache spark操作
- apache spark程序
Apache Spark 中国技术社区
阿里巴巴开源大数据技术团队成立 Apache Spark 中国技术社区,定期推送精彩案例,问答区数个 Spark 技术同学每日在线答疑,只为营造 Spark 技术交流氛围,欢迎加入!
+关注