
在EMR Serverless Spark中实现MongoDB读写操作
基于MongoDB官方提供的Spark Connector,EMR Serverless Spark可以在开发时添加对应的配置来连接MongoDB。本文为您介绍在EMR Serverless Spark环境中实现MongoDB的数据读取和写入操作。
用户画像分析案例加工数据-基于新版数据开发和Spark计算资源
本文为您介绍如何用Spark SQL创建外部用户信息表ods_user_info_d_spark以及日志信息表ods_raw_log_d_spark访问存储在私有OSS中的用户与日志数据,通过DataWorks的EMR Spark SQL节点进行加工得到目标用户画像数据,阅读本文后,您可以了解如何通过Spark SQL来计算和分析已同步的数据,完成数仓简单数据加工场景。
用户画像分析案例同步数据-基于新版数据开发和Spark计算资源
本文将介绍如何创建HttpFile和MySQL数据源以访问用户信息和网站日志数据,配置数据同步链路将这些数据同步到在环境准备阶段创建的OSS存储中,并通过创建Spark外表解析OSS中存储的数据。通过查询验证数据同步结果,确认是否完成整个数据同步操作。
ClickHouse与大数据生态集成:Spark & Flink 实战
在当今这个数据爆炸的时代,能够高效地处理和分析海量数据成为了企业和组织提升竞争力的关键。作为一款高性能的列式数据库系统,ClickHouse 在大数据分析领域展现出了卓越的能力。然而,为了充分利用ClickHouse的优势,将其与现有的大数据处理框架(如Apache Spark和Apache Flink)进行集成...
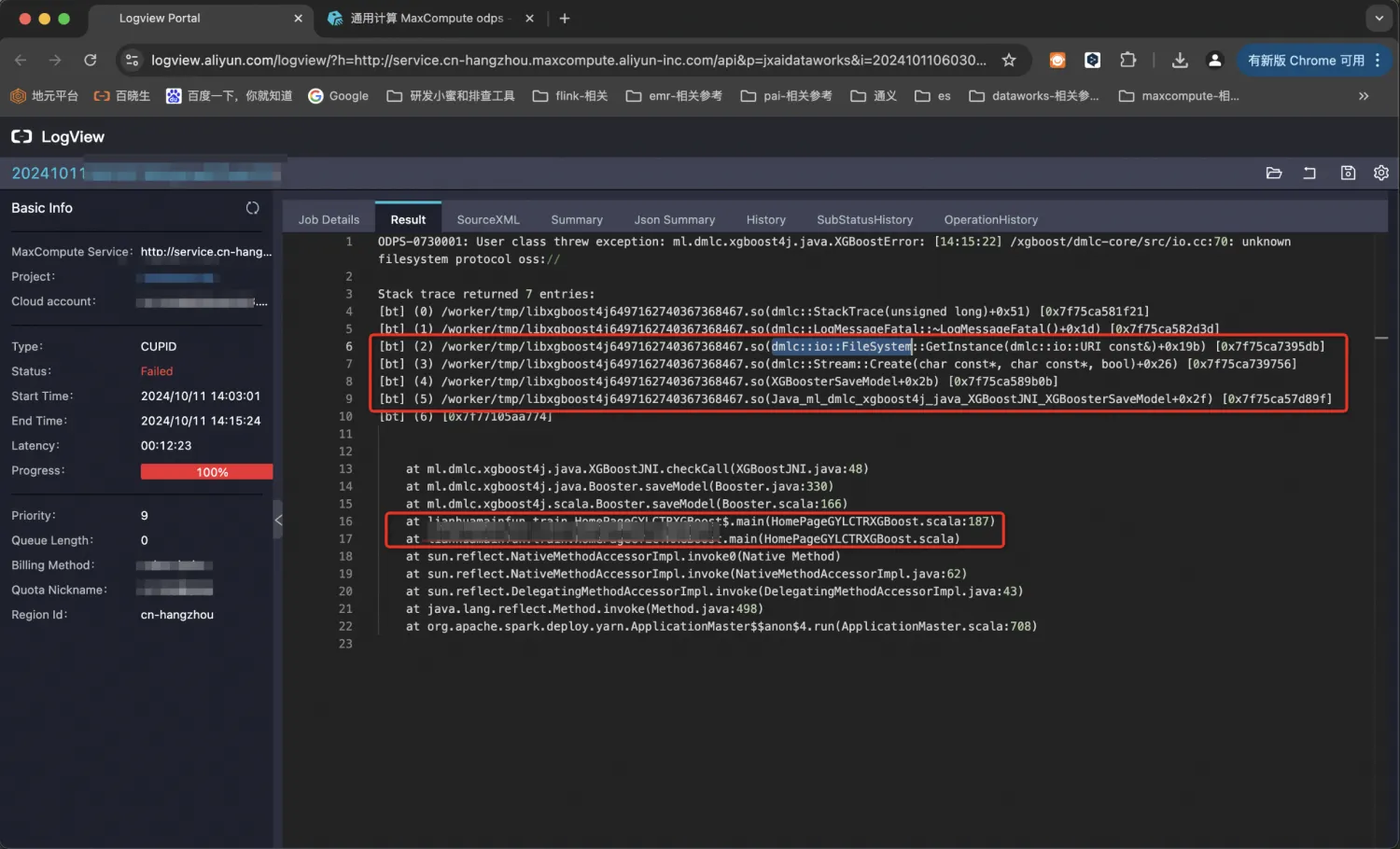
阿里云MaxCompute-XGBoost on Spark 极限梯度提升算法的分布式训练与模型持久化oss的实现与代码浅析
1. XGBoost简介 XGBoost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携。它在GBDT框架的基础上实现机器学习算法。XGBoost提供了并行树提升(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题。XGBoost最初是一个研究项目,孵化于Distributed (Deep) Machine Learning Community (DMLC) ,由陈天奇博...
AnalyticDB与大数据生态集成:Spark & Flink
在大数据时代,实时数据处理和分析变得越来越重要。AnalyticDB(ADB)是阿里云推出的一款完全托管的实时数据仓库服务,支持PB级数据的实时分析。为了充分发挥AnalyticDB的潜力,将其与大数据处理工具如Apache Spark和Apache Flink集成是非常必要的。本文将从我个人的角度出发,分享如何...
利用.NET进行大数据处理:Apache Spark与.NET for Apache Spark
随着信息时代的到来,大数据已经成为企业决策、科学研究和技术创新的重要驱动力。Apache Spark作为一个快速、通用的大数据处理引擎,广泛应用于各种大数据场景。然而,对于.NET开发者来说,如何在Spark生态系统中发挥自己的专长,将.NET的优势与Spark的能力结合起来,是一个值得探讨的话题。本文将介绍.N...
大数据平台的毕业设计02:Spark与实时计算
Spark、Kafka - 实时计算 现在提到实时计算,可能大家首先会想到flink。的确,flink在开源实时领域方面绝对算是TOP了。18年的时候,实时处理还是SparkStreaming应用的比较广泛。所以当时我安装的是Spark集群,来模拟的实时计算。 其实Spark/flink集群都是可以不搭建的,在Spark集群上运行程序属于standlone模式,如果使用yarn模...

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云原生大数据计算服务 MaxCompute更多spark相关
- spark云原生大数据计算服务 MaxCompute
- 开源spark云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute spark模型
- 云原生大数据计算服务 MaxCompute spark代码
- 云原生大数据计算服务 MaxCompute spark graphx
- 云原生大数据计算服务 MaxCompute spark redis
- 云原生大数据计算服务 MaxCompute spark学习
- 云原生大数据计算服务 MaxCompute spark scala
- 云原生大数据计算服务 MaxCompute spark计算
- 云原生大数据计算服务 MaxCompute spark案例
- 云原生大数据计算服务 MaxCompute spark任务
- 云原生大数据计算服务 MaxCompute spark节点
- 云原生大数据计算服务 MaxCompute spark集群
- 云原生大数据计算服务 MaxCompute spark资源
- 云原生大数据计算服务 MaxCompute spark模式
- 云原生大数据计算服务 MaxCompute框架spark
- 云原生大数据计算服务 MaxCompute spark配置
- 云原生大数据计算服务 MaxCompute spark访问
- 云原生大数据计算服务 MaxCompute spark运行
- 云原生大数据计算服务 MaxCompute spark实战
- 云原生大数据计算服务 MaxCompute spark sql
- 云原生大数据计算服务 MaxCompute spark版本
- 云原生大数据计算服务 MaxCompute spark设置
- 云原生大数据计算服务 MaxCompute spark引擎
- 云原生大数据计算服务 MaxCompute hive spark
- 云原生大数据计算服务 MaxCompute spark文件
- 云原生大数据计算服务 MaxCompute学习spark
- 云原生大数据计算服务 MaxCompute spark访问oss
- 云原生大数据计算服务 MaxCompute spark dstream
- 云原生大数据计算服务 MaxCompute spark概念
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute点燃
- 云原生大数据计算服务 MaxCompute智能电商
- 云原生大数据计算服务 MaxCompute购物
- 云原生大数据计算服务 MaxCompute算法
- 云原生大数据计算服务 MaxCompute脏数据
- 云原生大数据计算服务 MaxCompute实践
- 云原生大数据计算服务 MaxCompute潜能
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute oss
- 云原生大数据计算服务 MaxCompute分布式
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute产品
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute开发
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute odps
- 云原生大数据计算服务 MaxCompute平台
大数据计算 MaxCompute
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。
+关注