
用户画像分析案例环境准备-基于新版数据开发和Spark计算资源
本教程以用户画像为例,在华东2(上海)地域演示如何使用DataWorks完成数据同步、数据加工和质量监控的全流程操作。为了确保您能够顺利完成本教程,您需要准备教程所需的EMR Serverless Spark空间、DataWorks工作空间,并进行相关的环境配置。
Lindorm计算资源
若您要使用DataWorks进行Lindorm任务的开发、管理,需先将您的Lindorm实例绑定为DataWorks的Lindorm计算资源。绑定完成后,可在DataWorks中使用该计算资源进行数据同步和开发等操作。
如何进行资源弹性扩缩容
DataWorks实时同步任务支持为使用的资源配置弹性扩缩容,可根据预设周期对集成任务的资源组进行扩缩容,节约资源成本。本文将为您介绍资源弹性扩缩容的操作方式。
用户画像分析案例同步数据-基于新版数据开发和StarRocks计算资源
本教程以MySQL中的用户基本信息ods_user_info_d表和OSS中的网站访问日志数据user_log.txt文件为例,通过数据集成离线同步任务分别同步至StarRocks的ods_user_info_d_starrocks、ods_raw_log_d_starrocks表。旨在介绍如何通过DataWorks数据集成实现异构数据源间的数据同步,完成数仓数据同步操作。
用户画像分析案例同步数据-基于新版数据开发和Spark计算资源
本文将介绍如何创建HttpFile和MySQL数据源以访问用户信息和网站日志数据,配置数据同步链路将这些数据同步到在环境准备阶段创建的OSS存储中,并通过创建Spark外表解析OSS中存储的数据。通过查询验证数据同步结果,确认是否完成整个数据同步操作。
大数据增加分区优化资源使用
在大数据处理中,分区是一种常见的优化技术,用于提高查询性能并减少资源消耗。分区的基本思想是将大表中的数据根据一个或多个列的值分割成较小的、更易于管理的部分。每个部分称为一个“分区”,分区可以基于日期、范围、列表或其他逻辑条件来创建。 以下是几种常见的分区策略以及它们如何帮助优化资源使用: 1. 范围分区(Range Parti...
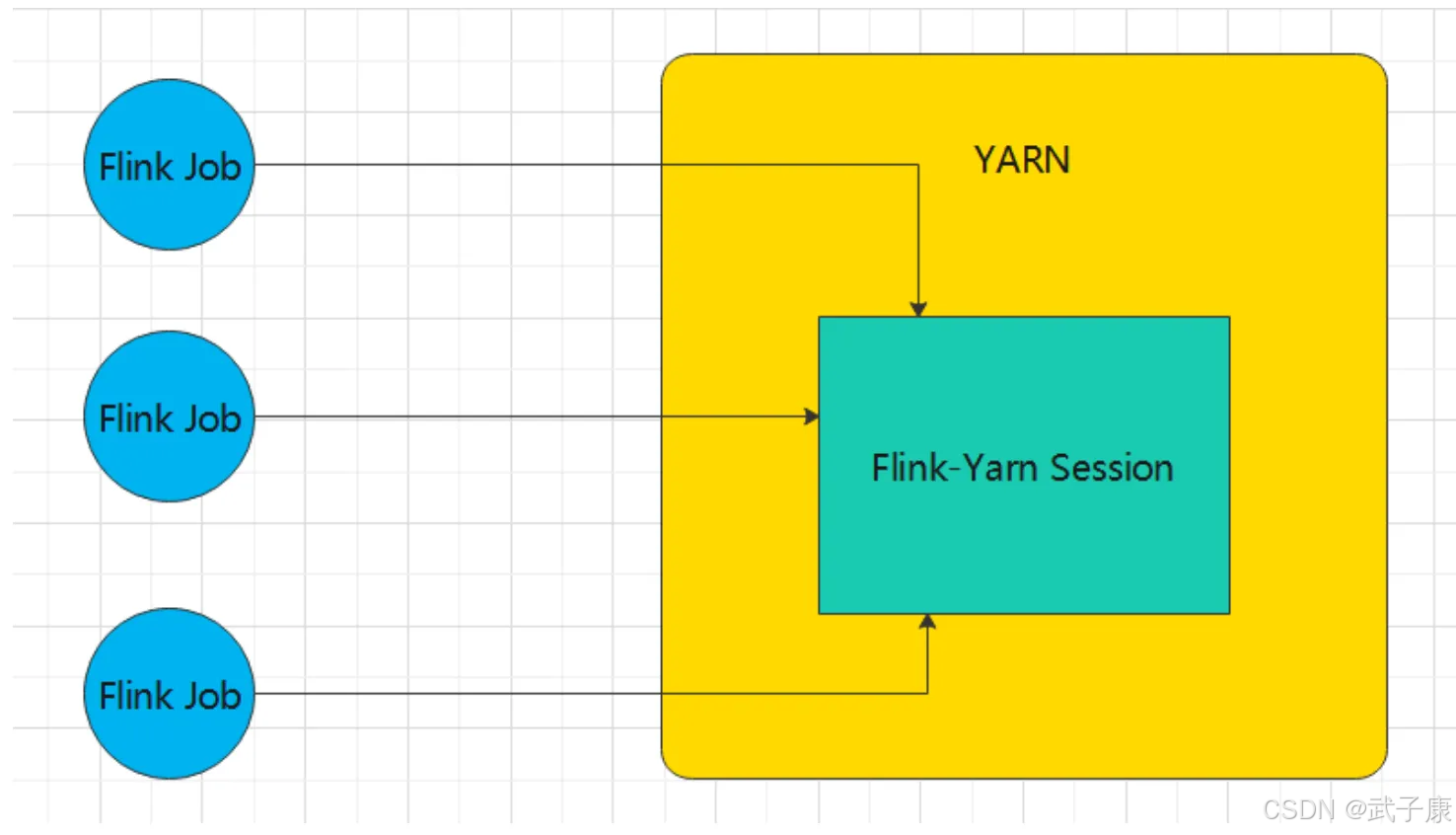
大数据-111 Flink 安装部署 YARN部署模式 FlinkYARN模式申请资源、提交任务
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...
大数据计算MaxCompute包月的计算资源qutota订单已经购买了 还能取消吗?怎么操作?
大数据计算MaxCompute包月的计算资源qutota订单已经购买了 还能取消吗?怎么操作?
在大数据计算MaxCompute中,资源花费这里区别是哪里?
在大数据计算MaxCompute中,实时同步数据接入这里,根据同步时间截取的分区年月日时单分区 和 默认的年月日时多层分区,资源花费这里区别是哪里?
在大数据计算MaxCompute中,本地执行的时候不用调度资源吗?
在大数据计算MaxCompute中,本地执行odps.ODPS(),max_frame.new_session()的时候不用调度资源吗?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云原生大数据计算服务 MaxCompute更多资源相关
- 资源云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute模式资源
- 云原生大数据计算服务 MaxCompute资源购买
- 数据计算云原生大数据计算服务 MaxCompute包月资源
- 云原生大数据计算服务 MaxCompute资源区别
- 数据计算云原生大数据计算服务 MaxCompute调度资源
- 云原生大数据计算服务 MaxCompute资源资源组
- 大数据云原生大数据计算服务 MaxCompute任务资源
- 云原生大数据计算服务 MaxCompute资源调度
- 云原生大数据计算服务 MaxCompute资源信息
- 云原生大数据计算服务 MaxCompute包年包月资源
- 云原生大数据计算服务 MaxCompute产品资源
- 云原生大数据计算服务 MaxCompute资源组资源
- 云原生大数据计算服务 MaxCompute独享资源
- 云原生大数据计算服务 MaxCompute mc资源
- 云原生大数据计算服务 MaxCompute运行资源
- 云原生大数据计算服务 MaxCompute资源cu
- 云原生大数据计算服务 MaxCompute资源库
- 云原生大数据计算服务 MaxCompute集群资源
- 云原生大数据计算服务 MaxCompute自定义资源
- 云原生大数据计算服务 MaxCompute jar资源
- 云原生大数据计算服务 MaxCompute节点资源
- 云原生大数据计算服务 MaxCompute资源计算资源
- 云原生大数据计算服务 MaxCompute文件资源
- 云原生大数据计算服务 MaxCompute包资源
- 数据计算云原生大数据计算服务 MaxCompute udf资源
- 云原生大数据计算服务 MaxCompute项目资源
- 云原生大数据计算服务 MaxCompute服务资源
- 大数据云原生大数据计算服务 MaxCompute集成资源
- 云原生大数据计算服务 MaxCompute quota资源
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute自动化
- 云原生大数据计算服务 MaxCompute营销
- 云原生大数据计算服务 MaxCompute mysql数据库
- 云原生大数据计算服务 MaxCompute sql语句
- 云原生大数据计算服务 MaxCompute mysql
- 云原生大数据计算服务 MaxCompute案例
- 云原生大数据计算服务 MaxCompute数据库
- 云原生大数据计算服务 MaxCompute策略
- 云原生大数据计算服务 MaxCompute调优
- 云原生大数据计算服务 MaxCompute方法
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute产品
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute开发
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute hadoop
