
大数据学习
学习大数据是一个既有趣又充满挑战的过程。它涉及多个方面,包括数据的收集、存储、处理、分析以及可视化等。下面是一些建议,帮助你开始学习大数据: 1. 基础知识 计算机科学基础:了解基本的数据结构、算法和编程语言(如Python或Java)。统计学与数学:掌握基本的概率论、统计学原理和线性代数知识。 2...
大数据体系知识学习(三):数据清洗_箱线图的概念以及代码实现
箱线图介绍 箱线图通过绘制数据的中位数、四分位数、最大值和最小值等信息,可以帮助检测数据中的异常值。在箱线图中,超出1.5倍四分位距的数据点被视为异常值。 箱线图代码 这段代码主要进行了以下几个操作: 创建一个包含异常值的数据集。 绘制这个数据集的箱线图。 计算箱线图中的异常值。 删除异常值。 可视化删除异常值后的数据,并标出异常值。 将异常值存入数组并打印出来。 import ...

大数据体系知识学习(二):WordCount案例实现及错误总结
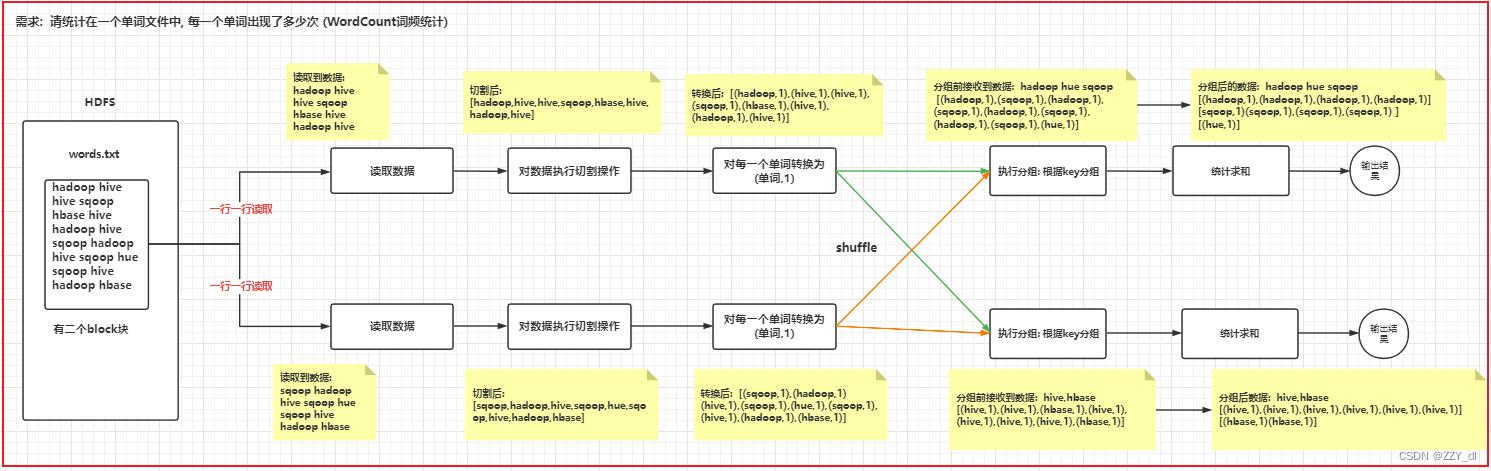
1. 当前环境 pyspark:版本号为3.1.2JAVA_JDK: 版本号为1.8.0_333Hadoop: 版本号为3.3.0 2. 相关信息 2.1 相关文件 words.txt如下 hello world hello hadoop hadoop hello world hive hive hive hadoop 2.2 相关流程 3. 运行代码 # spark入门案例 --- Wo...
大数据体系知识学习(一):PySpark和Hadoop环境的搭建与测试
1. 相关知识学习 1.1 Spark的基本介绍 Apache Spark是一个开源的大数据处理框架,使用内存计算方式加速大数据处理。Spark的主要优点包括高速批量处理、交互式查询、实时流处理以及机器学习等功能。**Spark由Scala语言实现,是一种面向对象、函数式编程语言,支持多种编程语言,如Scala、Java、Python和R等,可以运行在Hadoop集群上或者独立运行。**Spar....

大数据-106 Spark Graph X 计算学习 案例:1图的基本计算、2连通图算法、3寻找相同的用户
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...

大数据-88 Spark 集群 案例学习 Spark Scala 案例 SuperWordCount 计算结果数据写入MySQL
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...

大数据-87 Spark 集群 案例学习 Spark Scala 案例 手写计算圆周率、计算共同好友
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...

大数据-77 Kafka 高级特性-稳定性-延时队列、重试队列 概念学习 JavaAPI实现(一)
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(正在更新…) ...

大数据-77 Kafka 高级特性-稳定性-延时队列、重试队列 概念学习 JavaAPI实现(二)
接上篇:https://developer.aliyun.com/article/1622489?spm=a2c6h.13148508.setting.18.49764f0e90XaKU KafkaService package icu.wzk.service; import...
大数据-44 Redis 慢查询日志 监视器 慢查询测试学习
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (正在更新…) 章节内容 上节完成...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云原生大数据计算服务 MaxCompute更多学习相关
- 云原生大数据计算服务 MaxCompute学习概念
- 云原生大数据计算服务 MaxCompute学习环境
- 云原生大数据计算服务 MaxCompute学习案例
- 云原生大数据计算服务 MaxCompute学习scala
- 学习云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute hbase学习
- 云原生大数据计算服务 MaxCompute入门学习
- 云原生大数据计算服务 MaxCompute学习分组
- 云原生大数据计算服务 MaxCompute学习安装
- 云原生大数据计算服务 MaxCompute学习spark项目实战数据可视化
- 入门学习云原生大数据计算服务 MaxCompute
- 入门学习云原生大数据计算服务 MaxCompute学习报告
- mac云原生大数据计算服务 MaxCompute伪分布学习部署
- mac云原生大数据计算服务 MaxCompute伪分布学习环境部署
- 学习报告入门学习云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute导论案例学习
- mac构建云原生大数据计算服务 MaxCompute学习环境部署
- 云原生大数据计算服务 MaxCompute学习hive
- 云原生大数据计算服务 MaxCompute学习统计
- 云原生大数据计算服务 MaxCompute笔记学习
- 云原生大数据计算服务 MaxCompute学习步骤
- 转型云原生大数据计算服务 MaxCompute学习
- 构建云原生大数据计算服务 MaxCompute伪分布学习环境部署
- 概念学习云原生大数据计算服务 MaxCompute
- 好程序员云原生大数据计算服务 MaxCompute学习
- bat云原生大数据计算服务 MaxCompute工程师学习
- 云原生大数据计算服务 MaxCompute学习资源
- 学习云原生大数据计算服务 MaxCompute入手
- 学习云原生大数据计算服务 MaxCompute框架
- 云原生大数据计算服务 MaxCompute文档学习
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute点燃
- 云原生大数据计算服务 MaxCompute智能电商
- 云原生大数据计算服务 MaxCompute购物
- 云原生大数据计算服务 MaxCompute算法
- 云原生大数据计算服务 MaxCompute脏数据
- 云原生大数据计算服务 MaxCompute实践
- 云原生大数据计算服务 MaxCompute潜能
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute oss
- 云原生大数据计算服务 MaxCompute分布式
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute产品
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute开发
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute odps
大数据计算 MaxCompute
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。
+关注