
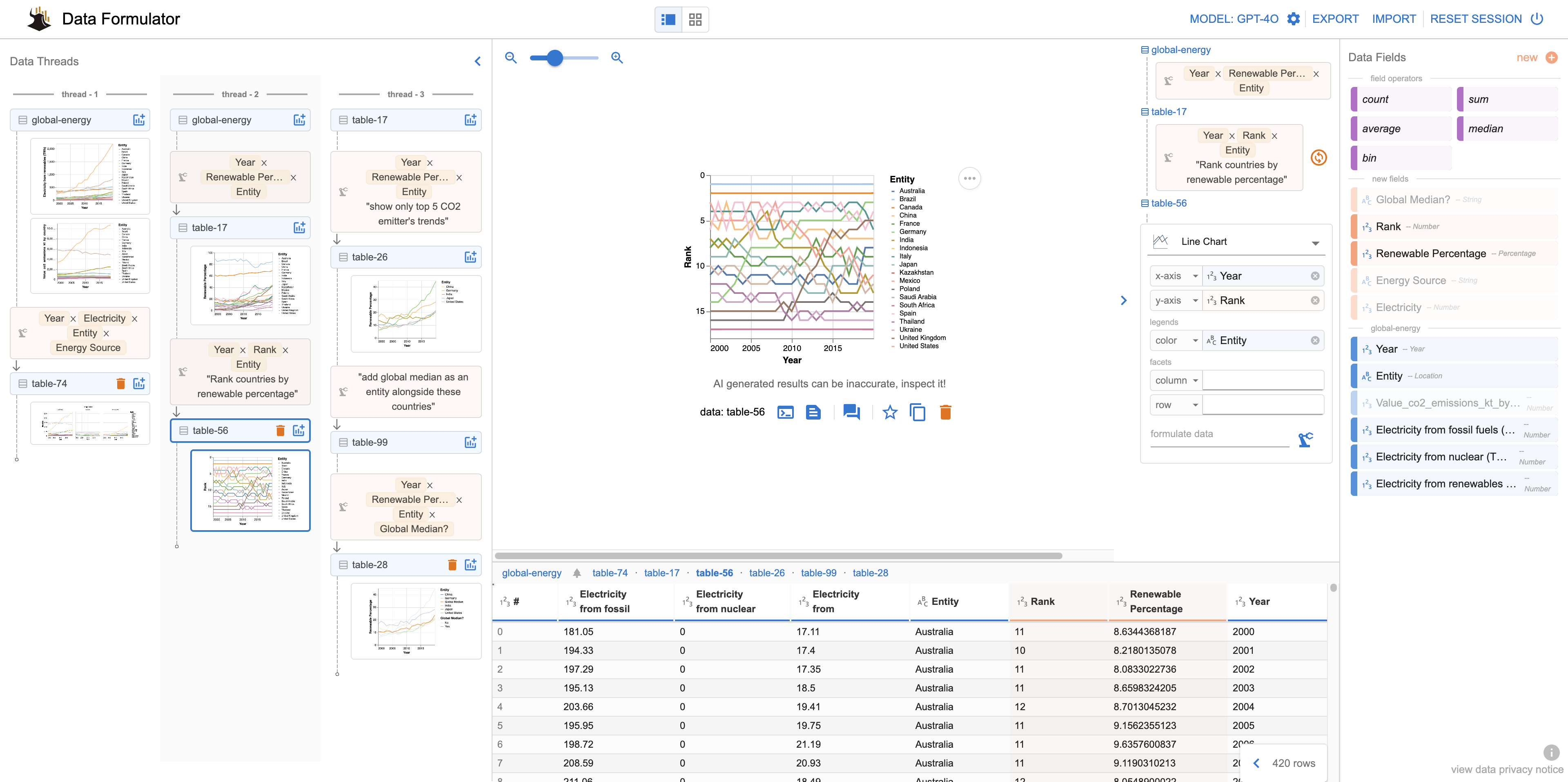
Data Formulator:微软开源的数据可视化 AI 工具,通过自然语言交互快速创建复杂的数据图表
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术! 微信公众号|搜一搜:蚝油菜花 大家好,我是蚝油菜花,今天跟大家分享一下 Data Formulator 这个由微软研究院推出的开源 AI 数据可视化工具。 快速阅读 Data Formulator 是一款强大的 AI 数据可...
探讨如何利用Python中的NLP工具,从被动收集到主动分析文本数据的过程
随着互联网的快速发展,海量的文本信息每天都在产生。如何从这些文本中提取有价值的信息并进行有效的分析成为了企业和研究者关注的重点。自然语言处理(Natural Language Processing, NLP)技术为解决这些问题提供了强大的工具。本文将通过具体的代码示例来探讨如何利用Python中的NLP工具,从被动收集到主动分析文本数据的过...
【NLP自然语言处理】文本特征处理与数据增强
学习目标 了解文本特征处理的作用.掌握实现常见的文本特征处理的具体方法 掌握实现常见的文本数据增强的具体方法 掌握常见的文本数据增强方法: 回译数据增强法 什么是n-gram特征 给定一段文本序列, 其中n个词或字的相邻共现特征即n-gram特征, 常用的n-gram特征是bi-gram和tri-gram特征,...
在 NLP 环境中,模型预训练和模型微调对于深度学习架构和数据意味着什么?
随着深度学习技术的发展,预训练(Pretraining)和微调(Fine-Tuning)已经成为自然语言处理(Natural Language Processing, NLP)领域的关键技术。这两种技术不仅改变了模型的训练方式,还大幅提升了模型在各种任务中的性能。本文将详细介绍模型预训...
在NLP自学习平台中,需要对一万条裁判文书数据进行文本关系抽取的模型训练,如何收费?
在NLP自学习平台中,需要对一万条裁判文书数据进行文本关系抽取的模型训练,如何收费?
探索机器学习中的自然语言处理技术网络安全与信息安全:保护数据的关键策略
自然语言处理(NLP)作为人工智能的一个重要分支,致力于使计算机能够理解和生成人类语言。随着技术的不断进步,NLP已经从简单的文本分类和关键词提取发展到了能够进行复杂的对话理解和机器翻译。 NLP的基础是对文本数据的预处理,包括分词、去除停用词、词干提取等。这些步骤虽然看似简单,却是后续高级任务的基石。分词是将连...
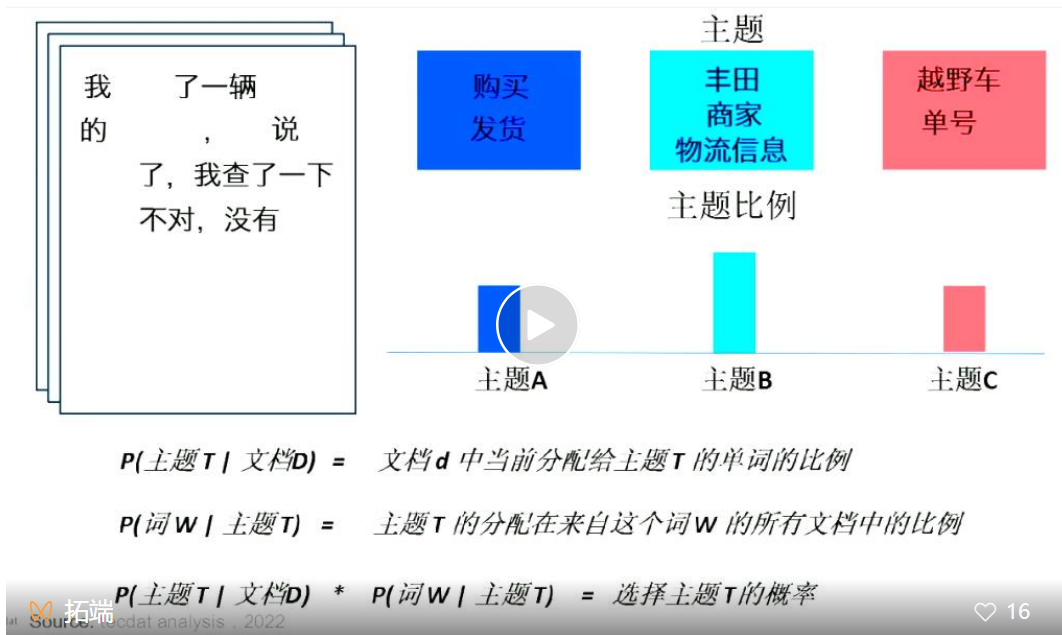
NLP自然语言处理—主题模型LDA案例:挖掘人民网留言板文本数据
随着网民规模的不断扩大,互联网不仅是传统媒体和生活方式的补充,也是民意凸显的地带。领导干部参与网络问政的制度化正在成为一种发展趋势,这种趋势与互联网发展的时代需求是分不开的(点击文末“阅读原文”获取完整代码数据)。 相关视频 ...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。