
优化大数据处理:Java与Hadoop生态系统集成
引言 随着数据规模的快速增长,大数据处理成为现代信息技术领域的重要课题之一。本文将探讨如何通过优化Java与Hadoop生态系统的集成,实现高效、可扩展的大数据处理。 Java与Hadoop生态系统的基础 1. Hadoop生态系统概述 Hadoop是一个开源的分布式存储和计算框架,其核心组件包括HDFS(分布式文件系统)和MapReduce(分布式计算模型),此...
优化大数据处理:Java与Hadoop生态系统集成
优化大数据处理:Java与Hadoop生态系统集成 随着数据规模的快速增长,大数据处理成为现代信息技术领域的重要课题之一。本文将探讨如何通过优化Java与Hadoop生态系统的集成,实现高效、可扩展的大数据处理。 Java与Hadoop生态系统的基础 1. Hadoop生态系统概述 Hadoop是一个开源的分布式存储和计算框架,其核心组件包...
如何优化Hadoop集群的内存使用?
如何优化Hadoop集群的内存使用? 优化Hadoop集群的内存使用对于提高整体性能和处理能力至关重要。以下是一些具体的策略和建议: 合理配置JVM参数调整NameNode和DataNode的JVM内存大小:根据集群的大小和存储的数据量,合理设置NameNode和DataNode的JVM内存参数[^2^]。例如,可以通过调整H...
Hadoop性能优化数据分区和复制策略优化
Hadoop性能优化中的数据分区和复制策略优化是确保Hadoop集群高效运行的关键部分。以下是关于这两个方面的详细优化建议: 数据分区优化 确保数据均匀分布: 数据的均匀分布可以避免某些节点负载过重,从而提高集群的整体性能。 根据数据的特点和查询需求,可以采用合适的分区策略,如按时间、地理位置等因素进行数据分区。 合理的分区策略: 合理的分区策...

【大数据】Hadoop 2.X和1.X升级优化对比
1.前言 本文是作者大数据系列中的一文 前文中我们从大数据的概论入手、分别聊了分布式文件系统的鼻祖GFS、分布式数据库的鼻祖Big Table、hadoop中的分布式文件系统HDFS、计算引擎Map Reduce、分布式数据库HBase。以上关于Hadoop的内容都是基于hadoop 1.X来聊的,Hadoop 1.X作为推出的第一个版本经过实战的检验发现还有诸多很需要优化的地方...

Hadoop性能优化硬件和网络优化
Hadoop性能优化中的硬件和网络优化是提升Hadoop集群性能的关键环节。以下是关于Hadoop性能优化中硬件和网络优化的详细分析: 一、硬件优化 选择高性能的CPU:Hadoop集群中的节点需要处理大量的数据,因此选择高性能的CPU对于提高处理速度至关重要。根据具体的应用场景和数据量,可以选择多核、高主频的CPU来满足需求。 增加内存容量:Hadoop在处理数据时,需要频繁地进行数...

Hadoop性能优化优化元数据管理
Hadoop性能优化中的元数据管理是一个关键方面,它直接影响到Hadoop系统的性能和稳定性。以下是一些关于如何优化Hadoop元数据管理的建议: 合理设置数据块大小: Hadoop的默认数据块大小通常为128MB。但在实际应用中,根据数据规模和硬件配置进行合理的调整能够提升性能。 较小的数据块大小适用于处理大量小文件,但会增加元数据的开销。 较大的数据块大小则适...

Hadoop 集群小文件归档 HAR、小文件优化 Uber 模式
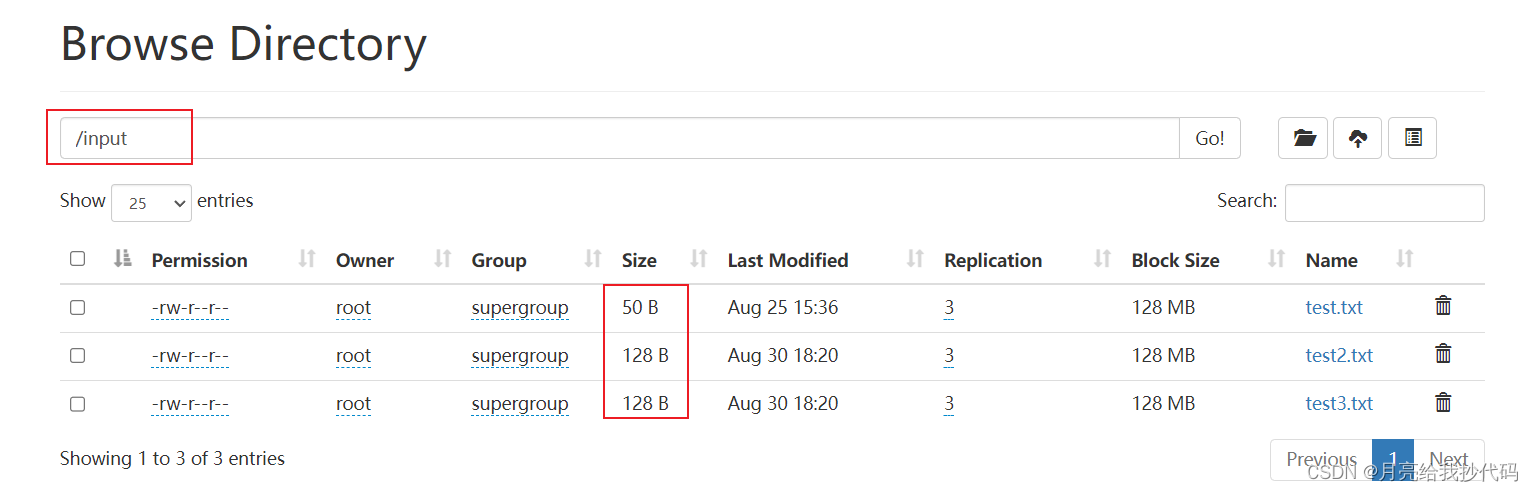
@[toc] 小文件归档 HAR 小文件归档是指将大量小文件合并成较大的文件,从而减少存储开销、元数据管理的开销以及处理时的任务调度开销。 这里我们通过 Hadoop Archive (HAR) 来进行实现,它是一种归档格式,可以将多个小文件和目录归档成单个 HAR 文件。 在进行下面的操作前,请先启动集群。 对小文件进行归档 当前,在 /input 目录下存储了 3 个小...
hadoop sdk 优化小结(裁剪、集成kerberos组件、定制等)
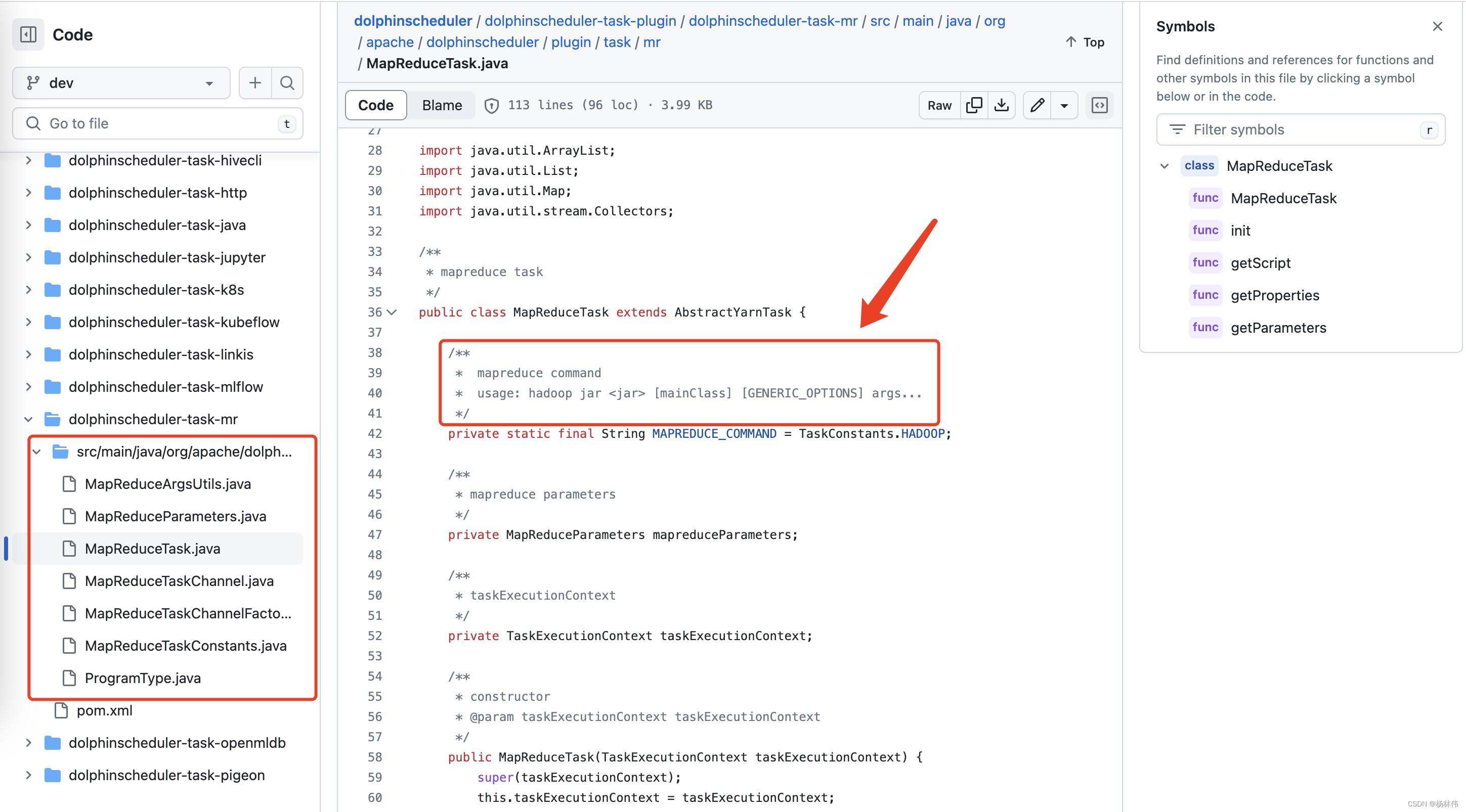
01 引言博主最近在实际的业务中,使用到了DolphinScheduler(一款大数据调度框架)里面的一个工作流的MapReduce任务节点。主要做的事情就是,在该节点提交一个mr作业到华为云MRS大数据平台里面的yarn,任务节点代码如下:从代码得知,它是使用CLI的形式提交作业的,因此需要解决如下几个问题:q1:需要有一个hadoop的安装包;q2: hadoop安装包体积过大,需要裁剪,否....
hadoop sdk 优化小结(裁剪、集成kerberos组件、定制等)
01 引言 博主最近在实际的业务中,使用到了DolphinScheduler(一款大数据调度框架)里面的一个工作流的MapReduce任务节点。 主要做的事情就是,在该节点提交一个mr作业到华为云MRS大数据平台里面的yarn,任务节点代码如下: 从代码得知,它是使用CLI的形式提交作业的,因此需要解决如下几个问题: q1:需要有一个hadoop的安装包; q2: hadoop安装...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
hadoop更多优化相关
hadoop您可能感兴趣
- hadoop spark
- hadoop技术
- hadoop大数据
- hadoop集群管理
- hadoop架构
- hadoop hdfs
- hadoop数据
- hadoop技术选型
- hadoop分布式
- hadoop系统
- hadoop集群
- hadoop安装
- hadoop配置
- hadoop mapreduce
- hadoop文件
- hadoop学习
- hadoop yarn
- hadoop hive
- hadoop命令
- hadoop运行
- hadoop节点
- hadoop搭建
- hadoop hbase
- hadoop部署
- hadoop报错
- hadoop实战
- hadoop概念
- hadoop启动
- hadoop操作
- hadoop apache