
Hadoop中运行Job
在Hadoop中运行Job的一般步骤如下: 编写MapReduce程序:首先,你需要有一个MapReduce程序。这可以是Java类或使用其他支持的语言编写的。 打包你的程序:你需要将你的MapReduce程序和所有依赖项打包成一个jar文件。你可以使用Maven或Ant等工具来帮助你完成这个任务。 准备输入数据:你需要将你的输入数据放入HDFS(Hadoop分布式文件系统)中。你...

Hadoop 配置Job使用Combiner来缓解数据倾斜
在Hadoop中,数据倾斜(Data Skew)是一个常见问题,它会导致某些节点处理的数据量远大于其他节点,从而拖慢整个作业的执行速度。使用Combiner可以在一定程度上缓解数据倾斜的问题,因为它可以在Map阶段对数据进行预聚合,减少传输到Reduce阶段的数据量。以下是如何配置Hadoop作业以使用Combiner来缓解数据倾斜的步骤: 1. 理解Combiner的作用 Combiner...

《Why is my Hadoop job slow》电子版地址
《Why is my Hadoop* job slow》Why is my Hadoop* job slow 电子版下载地址: https://developer.aliyun.com/ebook/1177 电子书: </div>

hadoop之多job串联(倒排索引案例)(15)
需求需求:有大量的文本(文档、网页),需要建立搜索索引原始数据a.txtmap reduce MapReduce index Inverted index Inverted index 倒排索引 大数据 hadoop MapReduce hdfs Inverted index 在这里插入代码片b.txthadoop MapReduce hdfs Inverted index 倒排索引 大数据 m....

Hadoop中的MapReduce框架原理、Shuffle机制、Partition分区、自定义Partitioner步骤、在Job驱动中,设置自定义Partitioner、Partition 分区案例
13.MapReduce框架原理13.2MapReduce工作流程上面的流程是整个MapReduce最全工作流程,但是Shuffle过程只是从第7步开始到第16步结束,具体Shuffle过程详解,如下:(1)MapTask收集我们的map()方法输出的kv对,放到内存缓冲区中(2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件(3)多个溢出文件会被合并成大的溢出文件(4)在溢出过程及合并的....
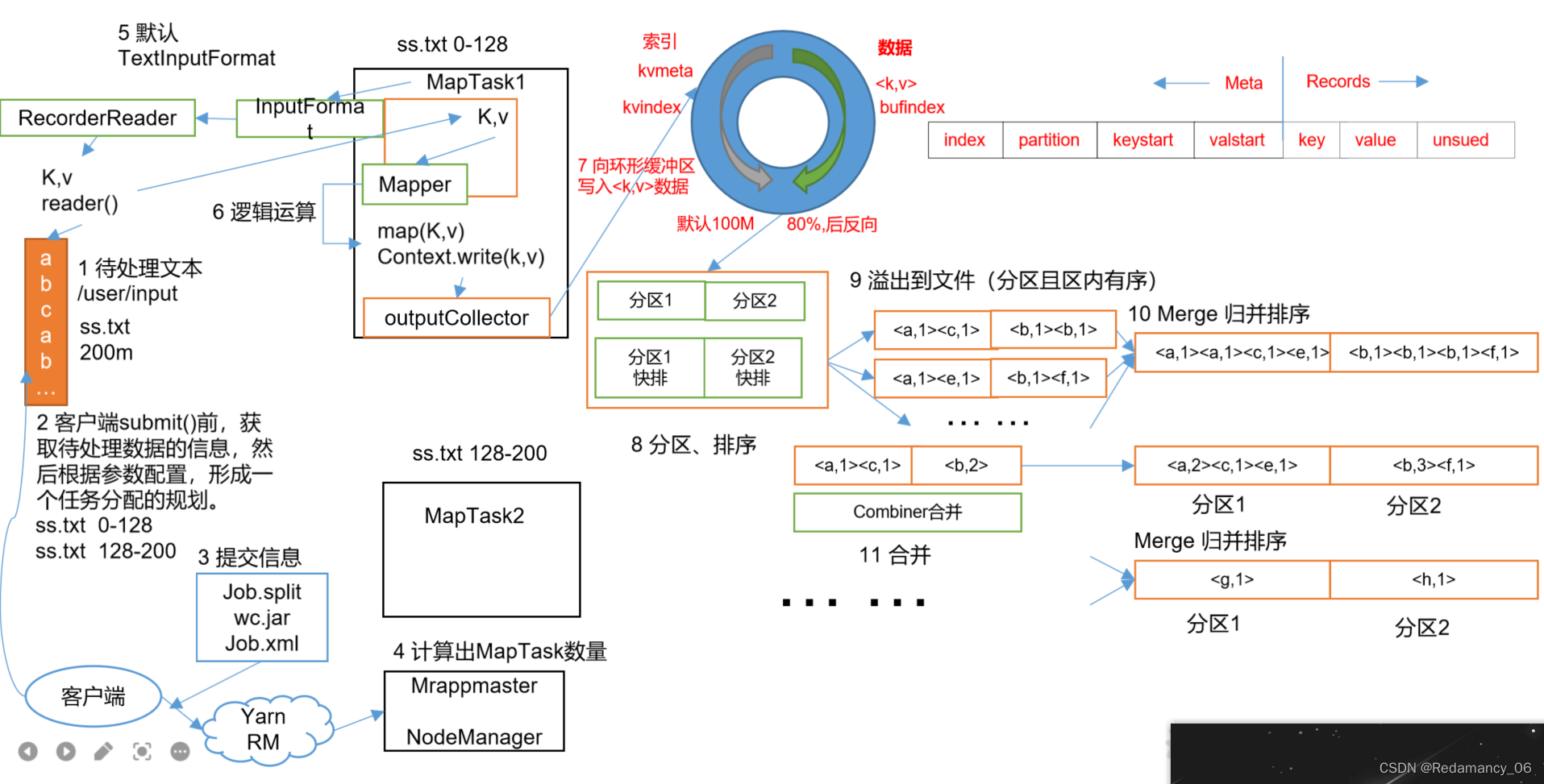
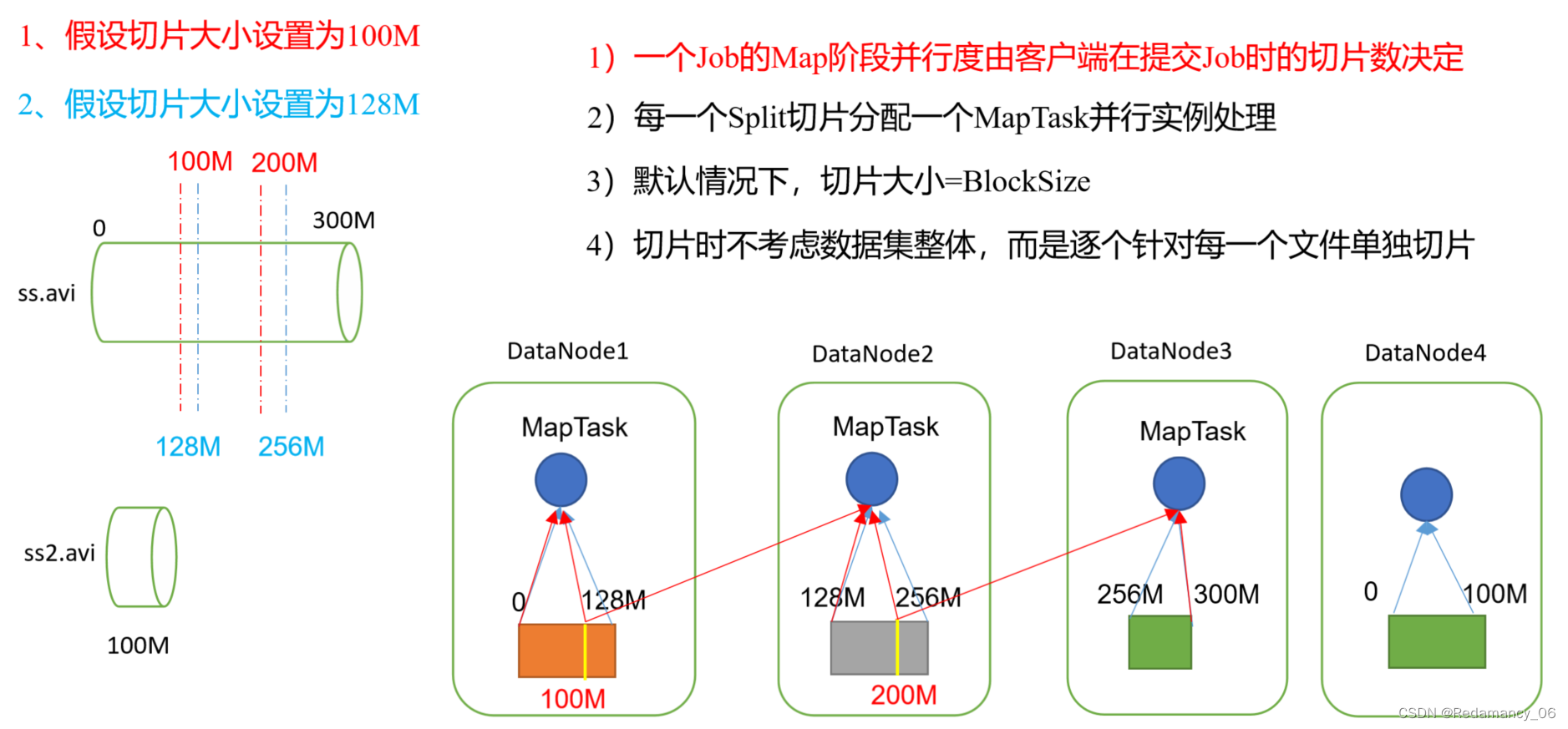
Hadoop中的MapReduce框架原理、Job提交流程源码断点在哪断并且介绍相关源码、切片与MapTask并行度决定机制、MapTask并行度决定机制
@[toc]13.MapReduce框架原理13.1InputFormat数据输入13.1.1切片与MapTask并行度决定机制13.1.1.1问题引出MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个Job的处理速度 思考:1G的数据,启动8个MapTask,可以提高集群的并发处理能力。那么1K的数据,也启动8个MapTask,会提高集群性能吗?MapTask并行任务是....
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
hadoop更多job相关
hadoop您可能感兴趣
- hadoop spark
- hadoop技术
- hadoop大数据
- hadoop集群管理
- hadoop架构
- hadoop hdfs
- hadoop数据
- hadoop技术选型
- hadoop分布式
- hadoop系统
- hadoop集群
- hadoop安装
- hadoop配置
- hadoop mapreduce
- hadoop文件
- hadoop学习
- hadoop yarn
- hadoop hive
- hadoop命令
- hadoop运行
- hadoop节点
- hadoop搭建
- hadoop hbase
- hadoop部署
- hadoop报错
- hadoop实战
- hadoop概念
- hadoop启动
- hadoop操作
- hadoop apache