
Hadoop数据倾斜自定义分区器
在Hadoop的MapReduce框架中,数据倾斜是一个常见的问题,它通常发生在数据没有均匀地分布到各个Reducer上的时候。数据倾斜会导致一些Reducer处理大量的数据,而其他Reducer则处于空闲状态,这会严重影响整个作业的执行效率。 自定义分区器(Partitioner)是解决数据倾斜问题的一种有效手段。默认情况下,Hadoop使用HashPartitioner类作为分区器,它基于.....

Hadoop数据倾斜使用自定义分区器
在Hadoop MapReduce中,数据倾斜通常是由于数据的非均匀分布导致的,特别是在Reduce阶段,当大量的数据被分配给少数几个Reducer时,这会导致某些Reducer处理大量的数据,而其他Reducer则处于闲置状态。为了解决这个问题,可以使用自定义分区器来更均匀地分配数据。 自定义分区器允许你控制如何将键映射到特定的Reducer上,从而避免数据倾斜。下面是一个使用自定义分区器的.....

Hadoop数据倾斜自定义分区器
在Hadoop中,数据倾斜是一个常见问题,特别是在MapReduce作业中,它可能导致某些Reducer节点负载过高,而其他节点却空闲,严重影响了整体处理效率。为了解决这个问题,可以采用自定义分区器(Partitioner)来更均匀地分布数据。 自定义分区器的作用 自定义分区器允许开发者基于自定义的逻辑来决定如何将Map阶段的输出分配给不同的Reduce任务。这样可以根据数据的特性设计分区策...

Hadoop序列化、概述、自定义bean对象实现序列化接口(Writable)、序列化案例实操、编写流量统计的Bean对象、编写Mapper类、编写Reducer类、编写Driver驱动类
@[toc]12.Hadoop序列化12.1序列化概述12.1.1什么是序列化序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储到磁盘(持久化)和网络传输。 反序列化就是将收到字节序列(或其他数据传输协议)或者是磁盘的持久化数据,转换成内存中的对象。12.1.2为什么要序列化一般来说,“活的”对象只生存在内存里,关机断电就没有了。而且“活的”对象只能由本地的进程使用,不能被....
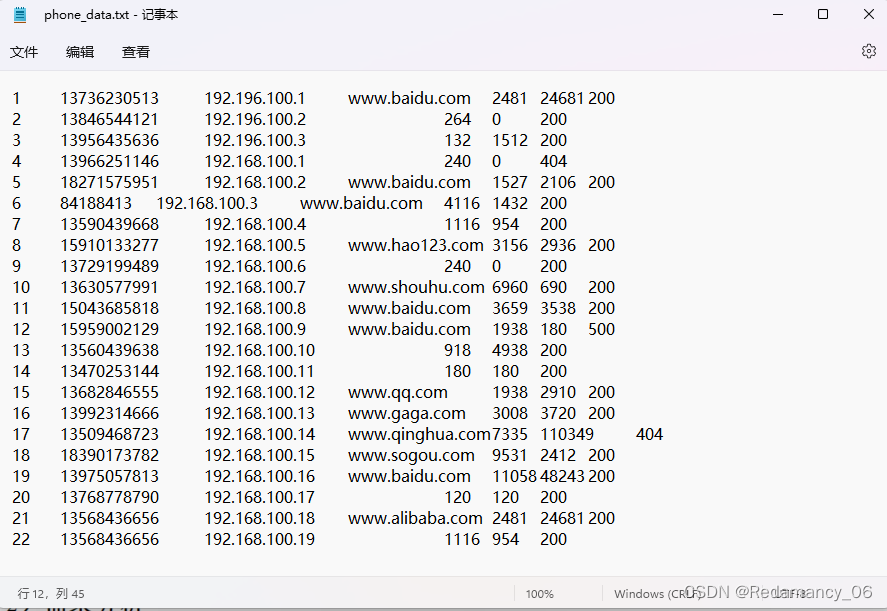
Hadoop中的MapReduce框架原理、Shuffle机制、Partition分区、自定义Partitioner步骤、在Job驱动中,设置自定义Partitioner、Partition 分区案例
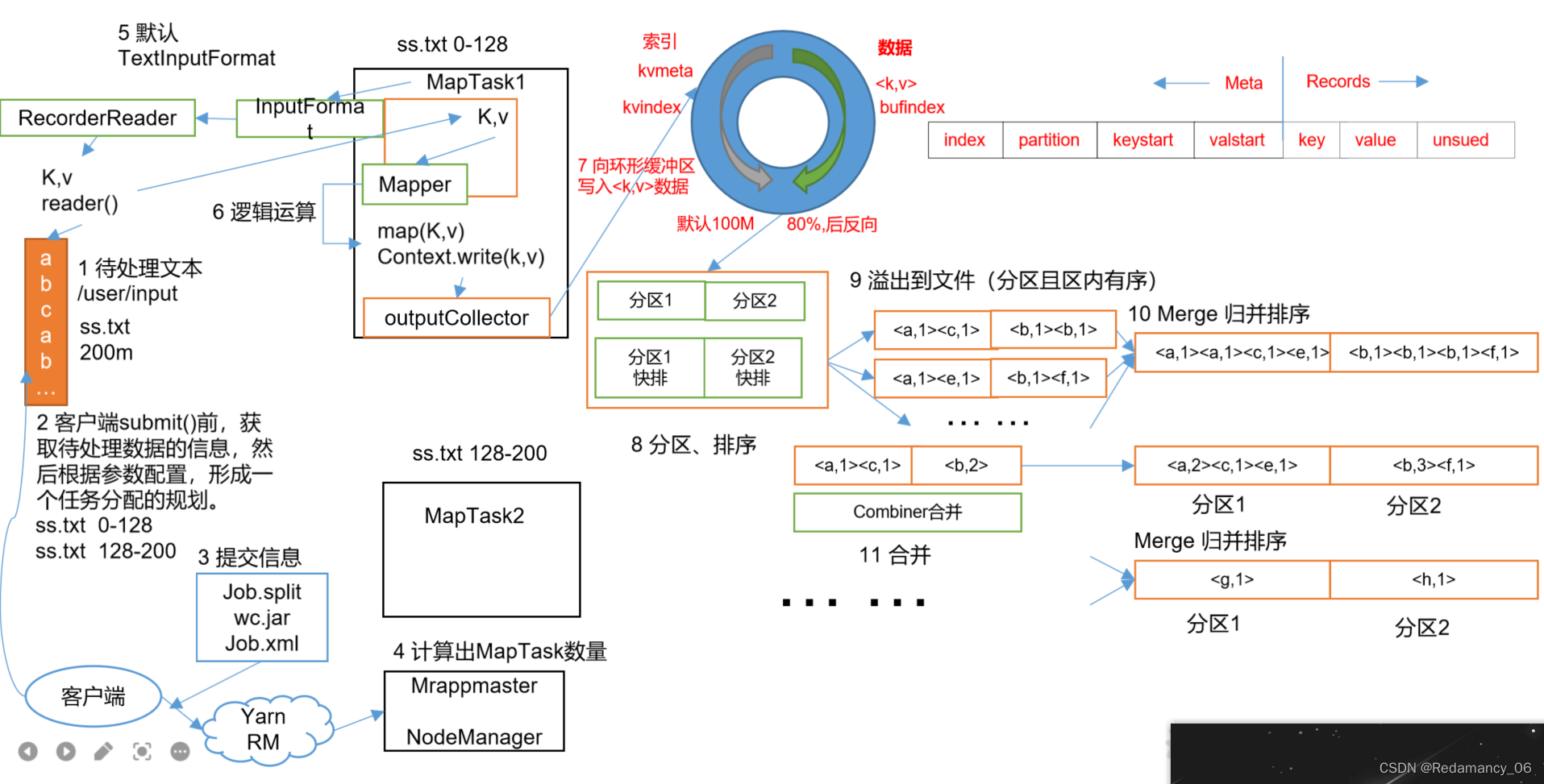
13.MapReduce框架原理13.2MapReduce工作流程上面的流程是整个MapReduce最全工作流程,但是Shuffle过程只是从第7步开始到第16步结束,具体Shuffle过程详解,如下:(1)MapTask收集我们的map()方法输出的kv对,放到内存缓冲区中(2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件(3)多个溢出文件会被合并成大的溢出文件(4)在溢出过程及合并的....
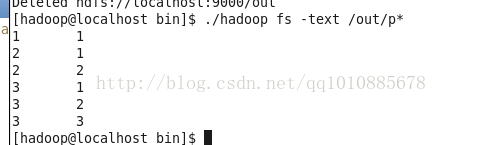
hadoop提交作业自定义排序和分组
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq1010885678/article/details/43736521 现有数据如下: 3 3 3 2 3 1 2 2 2 1 1 1 要求为: 先按第一列从小到大排序,如果第一列相同,按第二列从小到大排...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
hadoop更多自定义相关
hadoop您可能感兴趣
- hadoop入门
- hadoop系统
- hadoop spark
- hadoop技术
- hadoop大数据
- hadoop集群管理
- hadoop架构
- hadoop hdfs
- hadoop数据
- hadoop技术选型
- hadoop集群
- hadoop安装
- hadoop配置
- hadoop mapreduce
- hadoop分布式
- hadoop文件
- hadoop学习
- hadoop yarn
- hadoop hive
- hadoop命令
- hadoop运行
- hadoop节点
- hadoop搭建
- hadoop hbase
- hadoop部署
- hadoop报错
- hadoop实战
- hadoop概念
- hadoop启动
- hadoop操作