
基于ACK多机分布式部署DeepSeek满血版推理部署实战
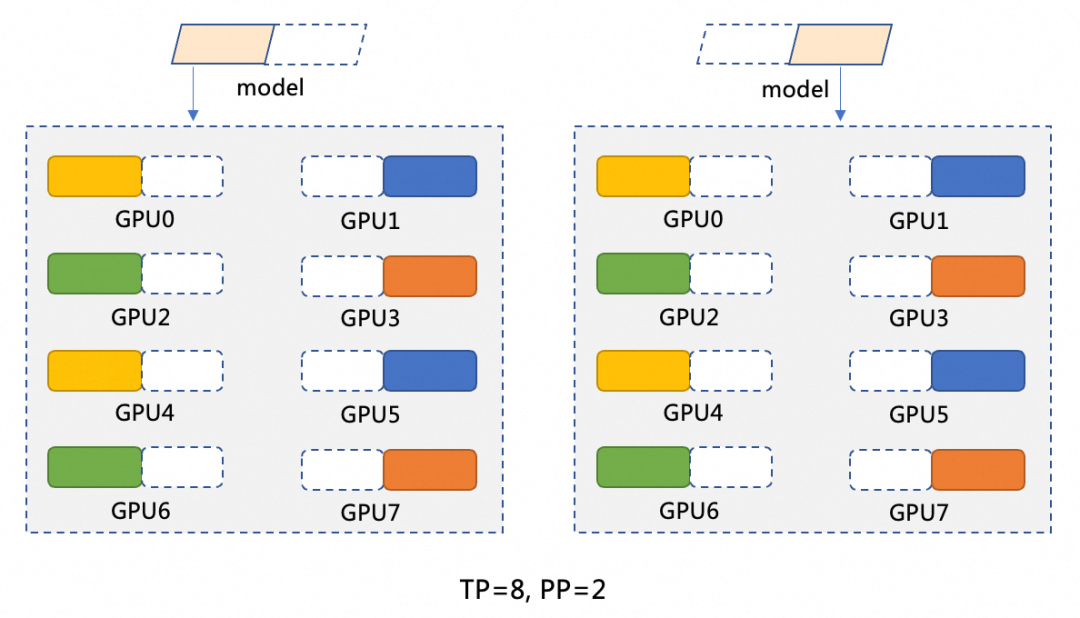
本文深入解析基于阿里云容器服务ACK的DeepSeek-R1-671B大模型分布式推理实战方案。针对该千亿参数模型(671B)单卡显存不足的挑战,提出混合并行策略(Pipeline Parallelism=2 + Tensor Parallelism=8),结合阿里云Arena工具,实现在2台ecs.ebmgn8v.48xlarge(8*96GB)节点上的高效分布式部署。进一步演示如何将部署于AC...
大道至简-基于ACK的Deepseek满血版分布式推理部署实战
本文是基于阿里云容器服务产品ACK,部署Deepseek大语言模型推理服务系列文章的第二篇。将介绍如何在Kubernetes管理的GPU集群中,快速部署多机分布式Deepseek-R1 671B(“满血版”)推理服务。并集成Dify应用,构建一个简单的Deepseek问答助手。关于如何在ACK部署Deepseek“蒸馏版”模型推理服务,可以参考本系列第一篇文章《基于ACK的DeepSeek蒸馏模....
大道至简-基于ACK的Deepseek满血版分布式推理部署实战
【阅读原文】戳:大道至简-基于ACK的Deepseek满血版分布式推理部署实战 本文是基于阿里云容器服务产品ACK,部署Deepseek大语言模型推理服务系列文章的第二篇。将介绍如何在Kubernetes管理的GPU集群中,快速部署多机分布式Deepseek-R1 671B(“满血版”)推理服务。并集成Dify应用,构建一个简单的Deepseek问答助手。关于如何在A...

Java中的分布式缓存与Memcached集成实战
Java中的分布式缓存与Memcached集成实战 一、概述 分布式缓存是提升系统性能和扩展性的关键技术之一。Memcached作为一种高性能的分布式内存对象缓存系统,在许多场景下被广泛使用。本文将深入探讨如何在Java项目中集成Memcached,实现高效的分布式缓存。 二、Memcached简介 Memcached是一种高效的分布式内存缓存系统,用于...
鸿蒙HarmonyOS应用开发 |鸿蒙技术分享HarmonyOS Next 深度解析:分布式能力与跨设备协作实战
鸿蒙技术分享:HarmonyOS Next 深度解析:分布式能力与跨设备协作实战 随着万物互联时代的到来,操作系统作为连接设备、应用与用户体验的核心,扮演着不可或缺的角色。华为最新发布的 HarmonyOS Next(鸿蒙操作系统下一代版本)不仅在技术架构上实现了颠覆性升级,更在生态体验上迈向了一个新的高度。本文将从 技术架构、生态优势 和 开发实践 三个方面深入探讨 HarmonyOS Nex....

探秘Redis分布式锁:实战与注意事项
大家好!我是小米,一个热爱分享技术的29岁技术达人。今天,我们来聊聊一个很有意思的主题——Redis分区容错之分布式锁。在分布式系统中,锁是一个非常重要的概念,它能确保系统中资源的并发访问不会出现问题。Redis作为一个流行的缓存和数据存储工具,它的分布式锁功能也备受关注。今天,我将带大家一起来了解Redis分布式锁的相关知识。 利用 Watch 实现 Redis 乐观锁 Redis的Wat...

HBase分布式数据库关键技术与实战:面试经验与必备知识点解析
作为一名长期关注并实践HBase技术的博主,我深知其在大数据领域尤其是NoSQL数据库中的独特价值及其在面试中的重要地位。本文将深入探讨HBase的关键技术、实战应用,以及面试必备知识点与常见问题解析,助你在面试中展现出深厚的HBase技术功底。 一、HBase核心技术 1.数据模型与表设计 解释HBase基于行键、列族、版本的三元组数据模型...
【分布式技术专题】「缓存解决方案」一文带领你好好认识一下企业级别的缓存技术解决方案的运作原理和开发实战(多级缓存设计分析)
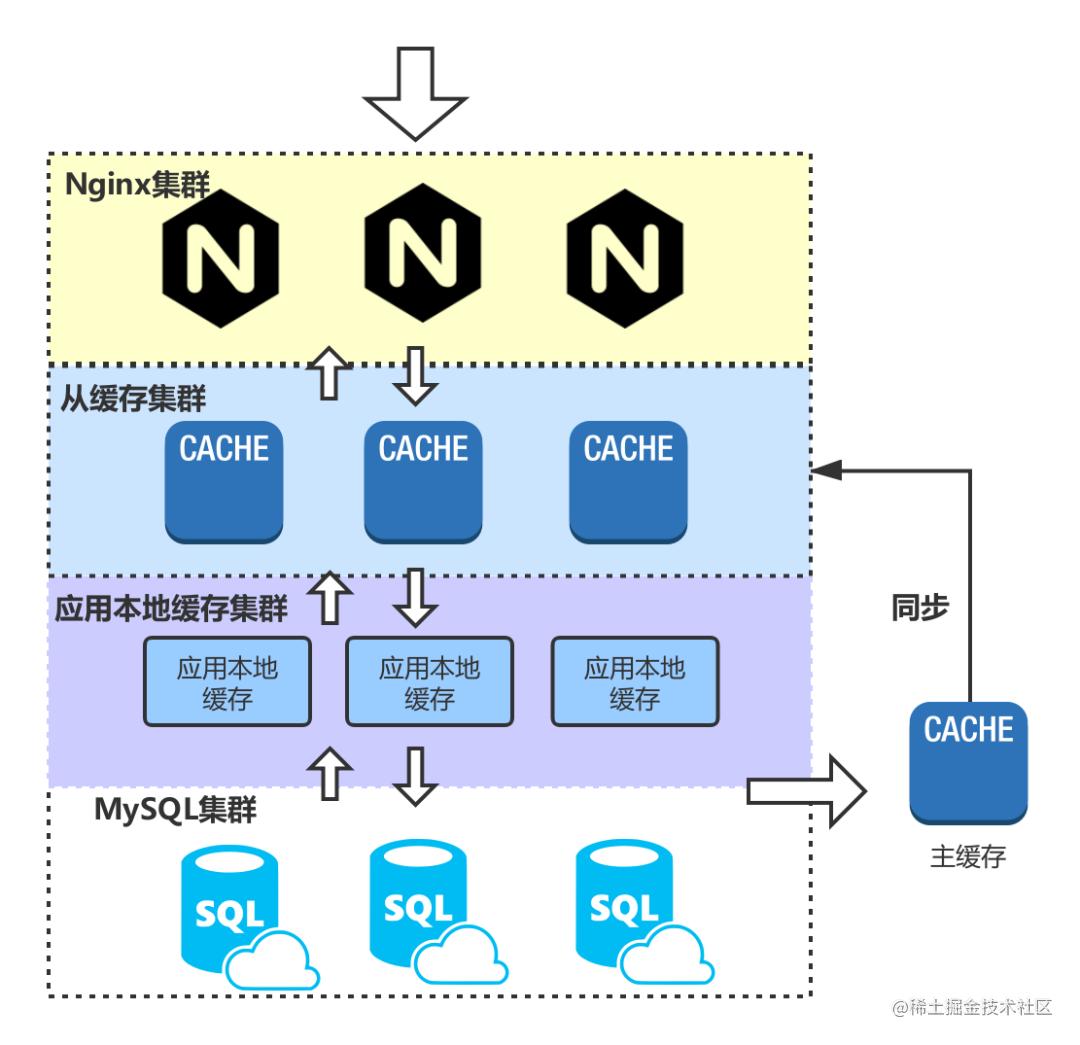
多级缓存设计案例 从用户发出请求到最底层的数据库,实际上会经过多个节点。因此,在整个链路上都可以设置缓存。根据缓存最近原则,将缓存放置在离用户最近的位置可以最大限度地提高系统响应效率,并明显提升系统的吞吐量,从而大大降低对后端的压力。 在整个链路流程中,可以添加缓存的地方包括:发起请求时的浏览器/客户端缓存、边缘缓存/CDN、反向代理(如Nginx)缓存、远程缓存、进程内缓存以及...
【分布式技术专题】「缓存解决方案」一文带领你好好认识一下企业级别的缓存技术解决方案的运作原理和开发实战(场景问题分析+性能影响因素)
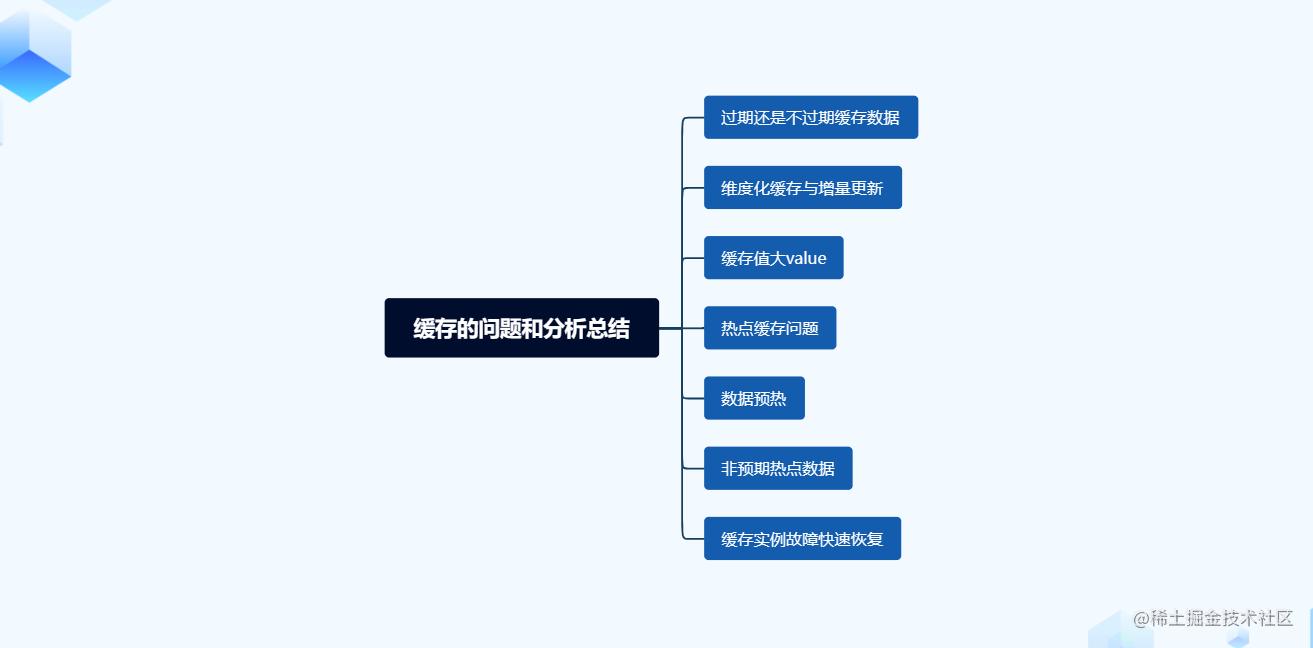
常见的几个场景问题 在仔细分析数据更新策略后,我们发现正确地使用缓存并不是一件容易的事情。而在实际应用中,还存在许多引人入胜的情景(或称为"坑"),在此我将对它们进行总结和归纳。 问题1:过期还是...
【分布式技术专题】「缓存解决方案」一文带领你好好认识一下企业级别的缓存技术解决方案的运作原理和开发实战(数据缓存不一致分析)
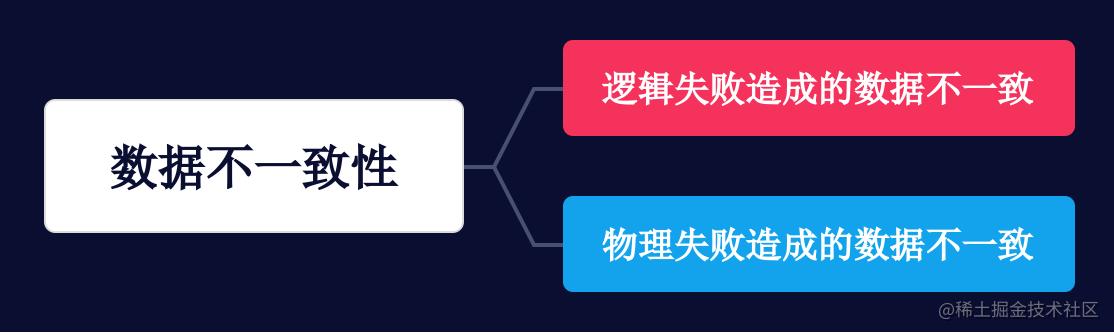
数据不一致的原因 在引入缓存后,数据就会分散在两个不同的数据源中。由于数据的更新是实时的,因此很难保持数据的一致性,除非采用强一致性方案。在探索适当的解决方案之前,我们需要分析导致数据不一致的主要原因,并针对性地解决这些问题: ...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
分布式更多实战相关
- 编程实战分布式
- python实战分布式
- 实战构建分布式
- 实战分布式
- 鸿蒙分布式实战
- 实战分布式订单
- 实战redisson分布式
- 实战分布式平台
- 实战分布式redisson
- 实战分布式功能
- ceph分布式实战
- springcloud实战分布式
- springcloud实战自研分布式生成器
- 大数据实战分布式
- dubbo分布式实战
- 分布式开发实战
- 实战企业级分布式
- 实战springcloud分布式
- 分布式实战数据
- 分布式实战单节点
- 分布式监控实战
- 入门zookeeper实战分布式
- springcloud alibaba实战分布式
- zabbix分布式监控实战
- hbase分布式实战
- 分布式实战案例
- 实战分布式缓存
- ceph分布式实战存储配置
- springcloud实战企业级分布式
- alibaba分布式实战
产品推荐

阿里云分布式应用服务
企业级分布式应用服务 EDAS(Enterprise Distributed Application Service)是应用全生命周期管理和监控的一站式PaaS平台,支持部署于 Kubernetes/ECS,无侵入支持Java/Go/Python/PHP/.NetCore 等多语言应用的发布运行和服务治理 ,Java支持Spring Cloud、Apache Dubbo近五年所有版本,多语言应用一键开启Service Mesh。
+关注