
【数据挖掘】十大算法之K-Means K均值聚类算法
1 Kmeans步骤 (1)数据预处理,如归一化、离群点处理等(2)随机选取K个簇中心,记为$$u_1^0, u_2^0, \ldots, u_k^0$$(3)定义代价函数,表示在一个簇内,各个样本距离所属簇中心点的误差平方和 $$J(c, u) = \sum_{i=1}^{k}\| x_i - u_{c_i} \|^{2} $$其中 xi表示第 i 个样本点, ci 是xi所属簇, uci...
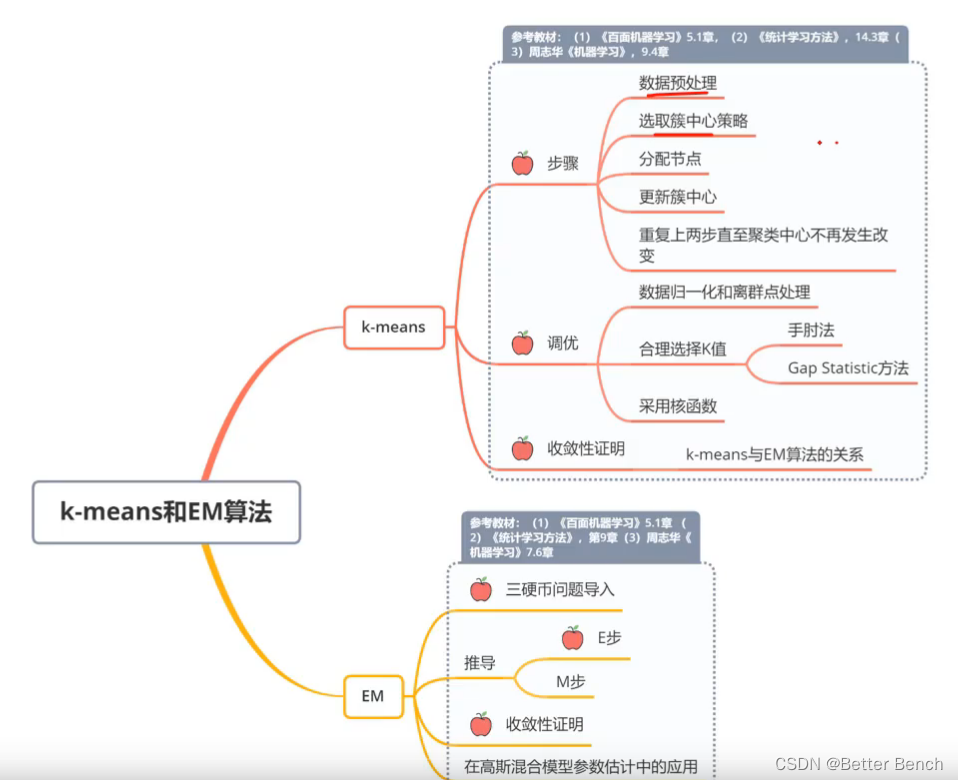
K-means聚类模型算法
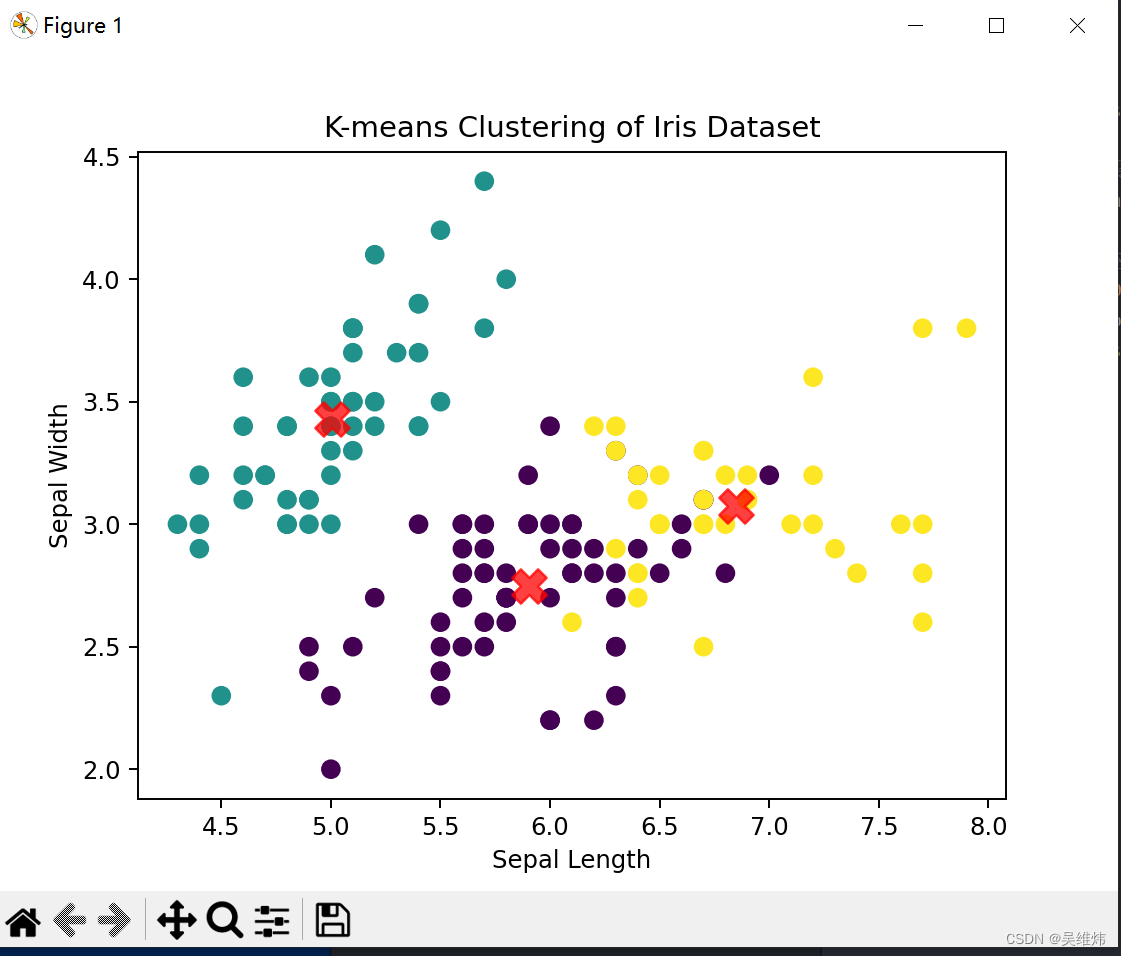
K-means聚类是一种无监督的机器学习算法,用于将数据点划分到K个不同的簇中。这种算法的目标是最小化簇内的方差,即使得每个簇内的数据点与簇中心的距离尽可能小。以下是K-means聚类模型的主要步骤和特点: 主要步骤: 1. 选择K值:确定要分成的簇的数量。 2. 初始化中心点:随机选择K个数据点作为初始的簇中心,或者使用K-means++算法来更智能...
「AIGC算法」K-means聚类模型
本文主要介绍K-means聚类模型原理及实践demo。 一、原理 K-means聚类是一种经典的、广泛使用的无监督学习算法,主要用于将数据集划分为多个类别或“簇”。其目标是将数据集中的每个点分配到K个聚类中心之一,使得簇内的点尽可能相似,而簇间的点尽可能不同。 K-means算法的基本步骤: 初始化:选择K个数据点作为初始聚类中心(质心)。 分配:将每个点分配到最近的聚类中...
机器学习算法入门:从K-means到神经网络
随着大数据和人工智能的快速发展,机器学习已成为解决复杂问题的有力工具。对于初学者来说,理解并掌握机器学习算法是迈向该领域的重要一步。本文将从简单的K-means算法开始,逐步介绍到更为复杂的神经网络,为你提供一个从基础到进阶的机器学习算法入门指南。 一、K-means聚类算法 K-means算法是一种无监督学习算法,主要用于数...
算法金 | 再见!!!K-means
\ 大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」 今天我们来聊聊达叔 6 大核心算法之 —— k-means 算法。最早由斯坦福大学的 J. B. MacQueen 于 1967 年提出,后来经过许多研究者的改进和发展,成为了一种经典的聚类方法。吴恩达:机器学习的六个核心算法! 分几部分,拿下: k...

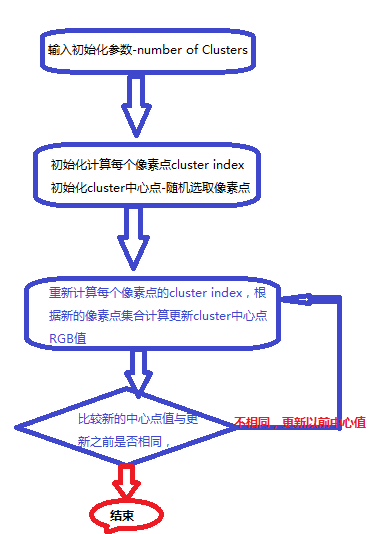
图像处理之K-Means算法演示
一:数学原理 K-Means算法的作者是MacQueen, 基本的数学原理很容易理解,假设有一个像素 数据集P。我们要根据值不同将它分为两个基本的数据集合Cluster1, Cluster2,使 用K-Means算法大致如下: 假设两个Cluster的RGB值分别为112,225,244和23,34,99则像素集合中的像素点...
【机器学习】K-means算法与PCA算法之间有什么联系?
联系与区别:K-means与PCA算法 K-means算法 K-means算法是一种常用的聚类算法,用于将数据点划分为不同的簇。该算法通过迭代的方式将数据点分配到离其最近的簇中心,并更新簇中心以使得簇内的数据点距离簇中心最小化。这一过程直到簇中心不再变化或者达到预设的迭代次数为止。K-means的主要思想是将数据点划分到不同的簇中,使得簇内的数据点相似度高,而不同簇之间的数据点相似度低。 ...

【机器学习】维度灾难问题会如何影响K-means算法?
引言 K-means算法是一种常用的无监督学习算法,用于将数据集划分为K个簇。然而,当数据集的维度非常高时,会导致维度灾难问题,从而影响K-means算法的性能和效果。本文将详细分析维度灾难问题对K-means算法的影响,并探讨应对方法。 维度灾难问题 问题描述 维度灾难是指随着数据维度的增加,数据空间的体积呈指数增长,导致数据点之间的距离变得越来越稀疏,从而影响了数据分布的表示和聚类算...

【机器学习】可以利用K-means算法找到数据中的离群值吗?
利用K-means算法检测离群值的可行性 引言 离群值(Outliers)是指与大多数数据点明显不同的数据点,它们可能是数据录入错误、测量误差、异常事件或真实但罕见的现象。在数据分析和异常检测中,识别和处理离群值是至关重要的任务之一。本文将探讨利用K-means算法检测离群值的可行性,并对其优劣势进行详细分析。 K-means算法的基本原理 K-means算法是一种基于质心的聚类算法,旨...

【机器学习】怎样在非常大的数据集上执行K-means算法?
在非常大的数据集上执行K-means算法是一个具有挑战性的任务,因为传统的K-means算法在处理大规模数据时会遇到一些问题,比如计算复杂度高、内存消耗大、收敛速度慢等。在本文中,我们将对在大规模数据集上执行K-means算法的挑战进行详细分析,并探讨如何利用并行计算、分布式计算和近似算法等技术来解决这些问题。 计算复杂度分析 在大规模数据集上执行K-means算法时,计算复杂度是一个非常重...

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
算法更多k-means相关
- k-means算法
- k-means聚类算法
- 算法k-means聚类
- k-means聚类算法分析
- 聚类k-means算法
- clustering k-means算法
- k-means算法步骤
- k-means算法微博
- k-means层次聚类算法
- r语言k-means均值聚类算法
- 数据挖掘k-means算法
- 聚类算法k-means
- 大数据k-means算法
- k-means均值算法
- k-means均值聚类算法
- hana分值硬聚类算法k-means
- hadoop k-means算法
- mahout k-means算法
- k-means算法优缺点
- sap pal硬聚类算法k-means
- 数据挖掘算法k-means

智能搜索推荐
智能推荐(Artificial Intelligence Recommendation,简称AIRec)基于阿里巴巴大数据和人工智能技术,以及在电商、内容、直播、社交等领域的业务沉淀,为企业开发者提供场景化推荐服务、全链路推荐系统开发平台、工程引擎组件库等多种形式服务,助力在线业务增长。
+关注