
利用.NET进行大数据处理:Apache Spark与.NET for Apache Spark
随着信息时代的到来,大数据已经成为企业决策、科学研究和技术创新的重要驱动力。Apache Spark作为一个快速、通用的大数据处理引擎,广泛应用于各种大数据场景。然而,对于.NET开发者来说,如何在Spark生态系统中发挥自己的专长,将.NET的优势与Spark的能力结合起来,是一个值得探讨的话题。本文将介绍.N...
大数据-166 Apache Kylin Cube 流式构建 整体流程详细记录
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...

大数据-165 Apache Kylin Cube优化 案例 2 定义衍生维度及对比 & 聚合组 & RowKeys
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...

大数据-164 Apache Kylin Cube优化 案例1 定义衍生维度与对比 超详细
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...

大数据-163 Apache Kylin 全量增量Cube的构建 手动触发合并 JDBC 操作 Scala
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...

大数据-162 Apache Kylin 全量增量Cube的构建 Segment 超详细记录 多图
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...

大数据-161 Apache Kylin 构建Cube 按照日期、区域、产品、渠道 与 Cube 优化
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...

大数据-160 Apache Kylin 构建Cube 按照日期构建Cube 详细记录
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...

大数据-159 Apache Kylin 构建Cube 准备和测试数据(一)
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完) HDFS(已更完) MapReduce(已更完) Hive(已更完) Flume(已更完) Sqoop(已更完) Zookeeper(已更完) HBase(已更完) Redis (已更完) Kafka(已更完) ...

大数据-159 Apache Kylin 构建Cube 准备和测试数据(二)
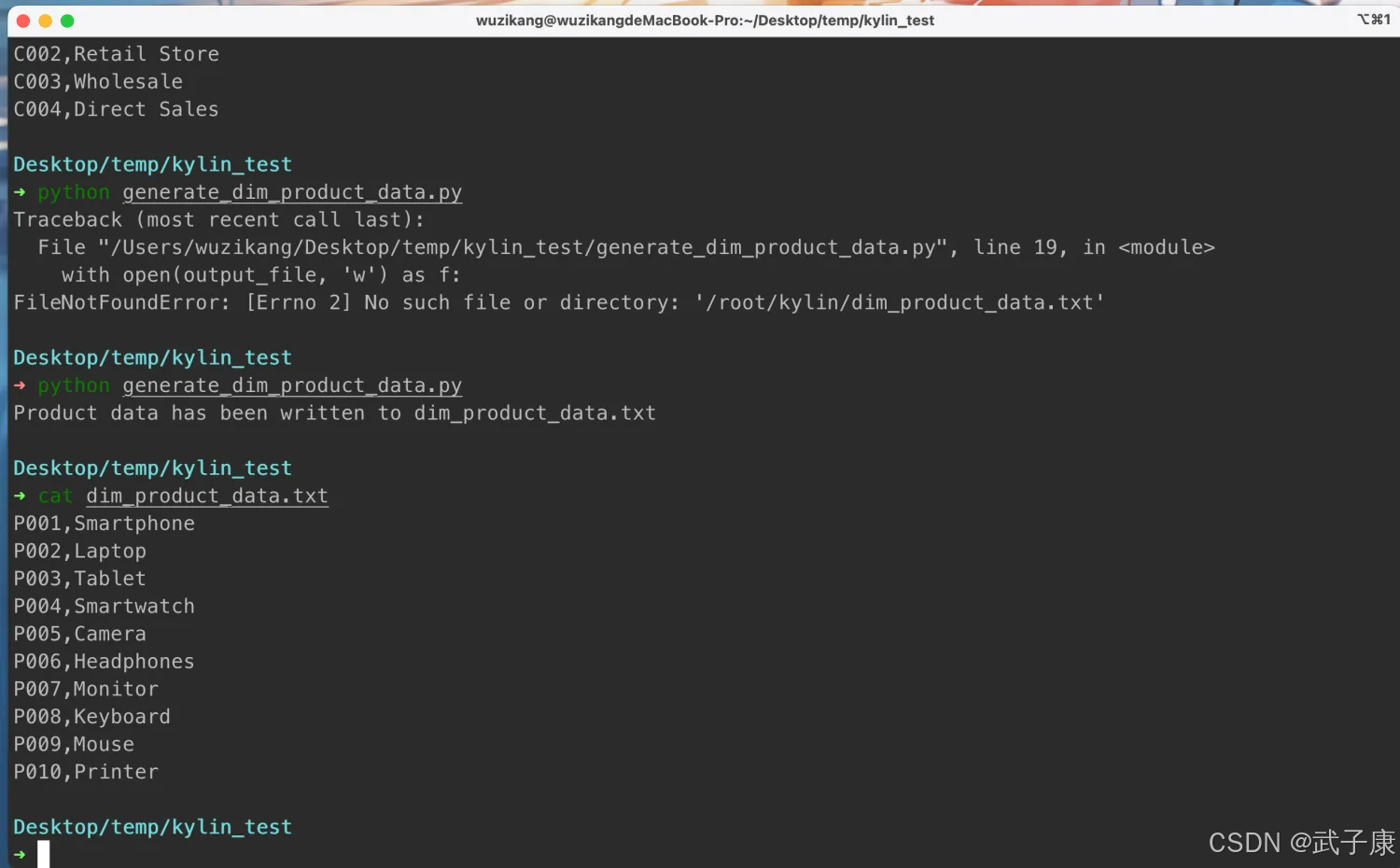
接上篇:https://developer.aliyun.com/article/1623254?spm=a2c6h.13148508.setting.18.66e24f0etlssu8 dim_product_data # 设置参数 output_file = 'dim_pro...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
云原生大数据计算服务 MaxCompute更多apache相关
- 云原生大数据计算服务 MaxCompute apache kylin
- 云原生大数据计算服务 MaxCompute apache cube
- 云原生大数据计算服务 MaxCompute apache流式
- 云原生大数据计算服务 MaxCompute apache scala
- 云原生大数据计算服务 MaxCompute apache场景
- 云原生大数据计算服务 MaxCompute apache druid
- 云原生大数据计算服务 MaxCompute apache kudu
- 云原生大数据计算服务 MaxCompute apache概述
- apache云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute apache apache spark
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute ai
- 云原生大数据计算服务 MaxCompute产品
- 云原生大数据计算服务 MaxCompute点燃
- 云原生大数据计算服务 MaxCompute智能电商
- 云原生大数据计算服务 MaxCompute购物
- 云原生大数据计算服务 MaxCompute算法
- 云原生大数据计算服务 MaxCompute脏数据
- 云原生大数据计算服务 MaxCompute实践
- 云原生大数据计算服务 MaxCompute潜能
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute开发
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute odps
- 云原生大数据计算服务 MaxCompute平台
大数据计算 MaxCompute
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。
+关注