
北大领衔,多智能体强化学习研究登上Nature子刊
近日,北京大学领导的研究团队在《Nature》子刊上发表了一篇关于多智能体强化学习的论文,引起了广泛关注。该研究提出了一种高效且可扩展的多智能体强化学习框架,旨在解决大规模网络控制系统中的决策问题。 在大规模系统中部署人工智能模型时,实现可扩展的决策制定是一个关键挑战。这需要系统实体之间进行有效的信息交换,以帮助智能体感知环境...
北大领衔,多智能体强化学习研究登上Nature子刊
近日,北京大学的研究团队在Nature子刊上发表了一篇关于多智能体强化学习(MARL)的论文,引起了广泛关注。该研究由北京大学的学者领衔,旨在解决大规模网络控制系统中的决策问题。 MARL是一种机器学习方法,它通过多个智能体之间的协作和竞争,实现对复杂系统的控制。在这项研究中,研究团队...
强化学习(Reinforcement Learning, RL)** 是一种机器学习技术,其中智能体(Agent)通过与环境(Environment)交互来学习如何执行决策以最大化累积奖励。
1. 强化学习与Gym模块概述 强化学习(Reinforcement Learning, RL) 是一种机器学习技术,其中智能体(Agent)通过与环境(Environment)交互来学习如何执行决策以最大化累积奖励。在强化学习中,智能体不会被告知应该采取什么行动,而是必...
Python强化学习应用于数据分析决策策略:** - 强化学习让智能体通过环境互动学习决策。
强化学习在数据分析中的应用:使用Python制定决策策略随着大数据时代的到来,数据分析和决策制定成为企业成功的关键因素。强化学习是一种机器学习技术,通过学习从环境中获取奖励来制定决策策略。Python作为一种功能强大、简单易学的编程语言,在强化学习领域具有广泛的应用。本文将介绍如何使用Python进行强化学习,制定数据分析中的...
在MDP环境下训练强化学习智能体
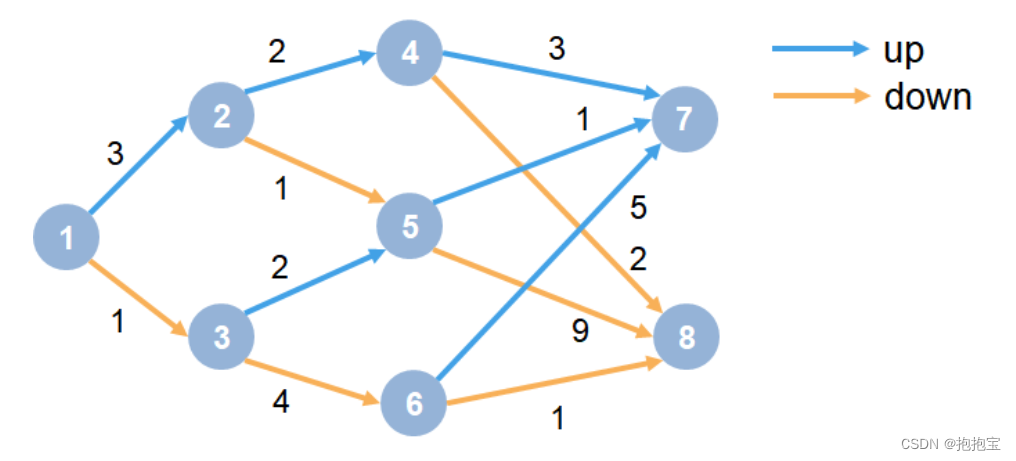
本文示例展示了如何训练Q-learning智能体来解决一般的马尔可夫决策过程(MDP)环境。有关这些智能体的更多信息,请参阅Q-Learning智能体。MDP环境如下图:其中:每一个圆圈代表一个状态。每个状态可以决定上升或下降。智能体从状态1开始。智能体收到的奖励等于图中每个转换的值。训练目标是获得最大的累积奖励。1.创建MDP环境创建具有8....
语言模型做先验,统一强化学习智能体,DeepMind选择走这条通用AI之路
在智能体的开发中,强化学习与大语言模型、视觉语言模型等基础模型的进一步融合究竟能擦出怎样的火花?谷歌 DeepMind 给了我们新的答案。一直以来,DeepMind 引领了强化学习(RL)智能体的发展,从最早的 AlphaGo、AlphaZero 到后来的多模态、多任务、多具身 AI 智能体 Gato,智能体的训练方法和能力都在不断演进。从中不难发现,随着大模型越来越成为人工智能发展的主流趋势,....

基于模型的多智能体强化学习中的模型学习理解
环境模型需要学习两个函数:状态转移函数,和奖励函数。多个智能体整体联合学习此时环境模型的学习与单智能体的学习并无太大差别,无非是观测空间维度扩大,动作空间维度扩大。此类建模方式优点:原理简单,较好实现。此类建模方式缺点:在此类模型中也可以做多尺度,此时的多尺度是整体上的多尺度,并非具体到每个单个智能体上的多尺度。因此整体上来看,具备一定的丰富采样规划的能力,但是并没有具体到每个单个智能体,多尺度....

多智能体强化学习(二) MAPPO算法详解
MAPPO论文全称为:The Surprising Effectiveness of MAPPO in Cooperative, Multi-Agent Games 这篇文章属于典型的,我看完我也不知道具体是在哪里创新的,是不是我漏读了什么,是不是我没有把握住,论文看一半直接看代码去了,因此后半截会有一段代码的解析。其实工作更多的我觉得是工程上的trick,思想很简单,暴力出奇迹。多智能体....

多智能体强化学习(一) IQL、VDN、QMIX、QTRAN算法详解
一个完全合作式的多智能体任务(我们有n个智能体,这n个智能体需要相互配合以获取最大奖励)可以描述为去中心化的部分可观测马尔可夫决策模型(Dec-POMDP),通常用一个元组G GG来表示:IQLIQL论文全称为:MultiAgent Cooperation and Competition with Deep Reinforcement Learning 多智能体环境中,状态转移和奖励函数都是....

【NIPS 2017】基于深度强化学习的想象力增强智能体
论文题目:Imagination-Augmented Agents for Deep Reinforcement Learning所解决的问题?背景最近也是有很多文章聚焦于基于模型的强化学习算法,一种常见的做法就是学一个model,然后用轨迹优化的方法求解一下,而这种方法并没有考虑与真实环境的差异,导致你求解的只是在你所学model上的求解。解决这种问题就是Dyna架构通过切换world mod....

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
通义星尘更多强化学习相关
通义大模型
通义千问大模型家族全面升级更大参数规模模型首次面世,全新通义千问2.0版本欢迎体验。https://tongyi.aliyun.com/
+关注